Apache Zeppelin 安装 测试链接 hive kerberos
基本概念
paragraph是zeppelin里面编写与运行代码的最小单元。 Note是paragraph的集合。Notebook是note的集合。 interpreter解释器、引擎,需要配置。
jdk配置,1.8 (151+ set JAVA_HOME)
[zeppelin@ecs-localhost ~]$ mv jdk-8u231-linux-x64.tar.gz /data/zeppelin/
[zeppelin@ecs-localhost ~]$ mv zeppelin-0.10.0-bin-all.tgz /data/zeppelin/
[zeppelin@ecs-localhost ~]$ cd /data/zeppelin/
[zeppelin@ecs-localhost zeppelin]$ tar xf jdk-8u231-linux-x64.tar.gz
[zeppelin@ecs-localhost ~]$ vim .bash_profile
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:$HOME/.local/bin:$HOME/bin
export JAVA_HOME=/data/zeppelin/jdk1.8.0_231
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export PATH
[zeppelin@ecs-localhost ~]$ source .bash_profile
安装,我使用的是完整包
[zeppelin@ecs-localhost ~]$ cd /data/zeppelin/
[zeppelin@ecs-localhost zeppelin]$ ll
total 1754624
drwxr-xr-x 7 zeppelin zeppelin 245 Oct 5 2019 jdk1.8.0_231
-rw-r--r-- 1 zeppelin zeppelin 194151339 Dec 30 2019 jdk-8u231-linux-x64.tar.gz
-rw-r--r-- 1 zeppelin zeppelin 1602577310 Jan 12 15:45 zeppelin-0.10.0-bin-all.tgz
[zeppelin@ecs-localhost zeppelin]$ tar xf zeppelin-0.10.0-bin-all.tgz
[zeppelin@ecs-localhost zeppelin-0.10.0-bin-all]$ cp conf/zeppelin-site.xml.template conf/zeppelin-site.xml
[zeppelin@ecs-localhost zeppelin-0.10.0-bin-all]$ vim conf/zeppelin-site.xml
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server binding address</description>
</property>
###启动
[zeppelin@ecs-localhost zeppelin-0.10.0-bin-all]$ ./bin/zeppelin-daemon.sh start
Please specify HADOOP_CONF_DIR if USE_HADOOP is true
Log dir doesn't exist, create /data/zeppelin/zeppelin-0.10.0-bin-all/logs
Pid dir doesn't exist, create /data/zeppelin/zeppelin-0.10.0-bin-all/run
Zeppelin start [ OK ]
配置账号访问,(默认匿名用户可以访问,使用shiro身份认证,https://zeppelin.apache.org/docs/0.10.0/setup/security/shiro_authentication.html)
[zeppelin@ecs-localhost conf]$ pwd
/data/zeppelin/zeppelin-0.10.0-bin-all/conf
[zeppelin@ecs-localhost conf]$ vim shiro.ini
##添加admin 密码password1, 用户权限格式:用户= 密码, 角色。 [roles]里面的规则默认有全部权限
[zeppelin@ecs-localhost conf]$ cp shiro.ini.template shiro.ini
[users]
admin = password1, admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
[zeppelin@ecs-localhost conf]$ cd ../
[zeppelin@ecs-localhost zeppelin-0.10.0-bin-all]$ ./bin/zeppelin-daemon.sh restart
配置你的本机kerberos客户端,过程省略
[root@ecs-localhost ~]# yum install krb5-workstation krb5-libs krb5-devel -y
登陆zeppelin配置hive
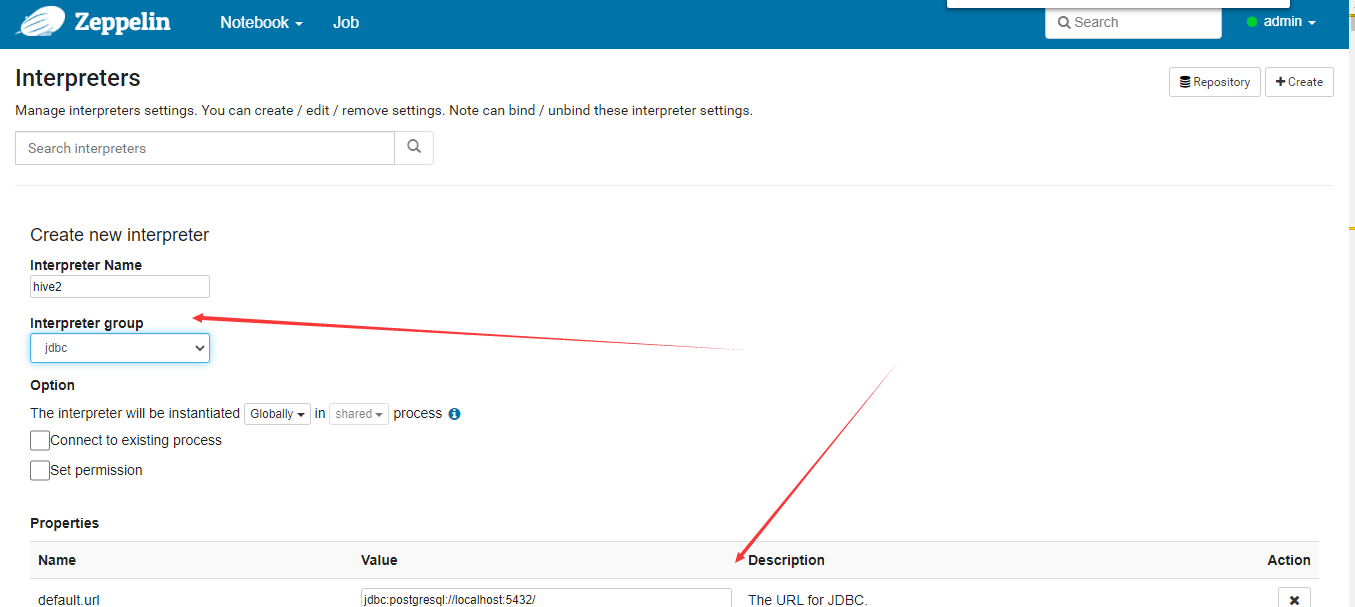
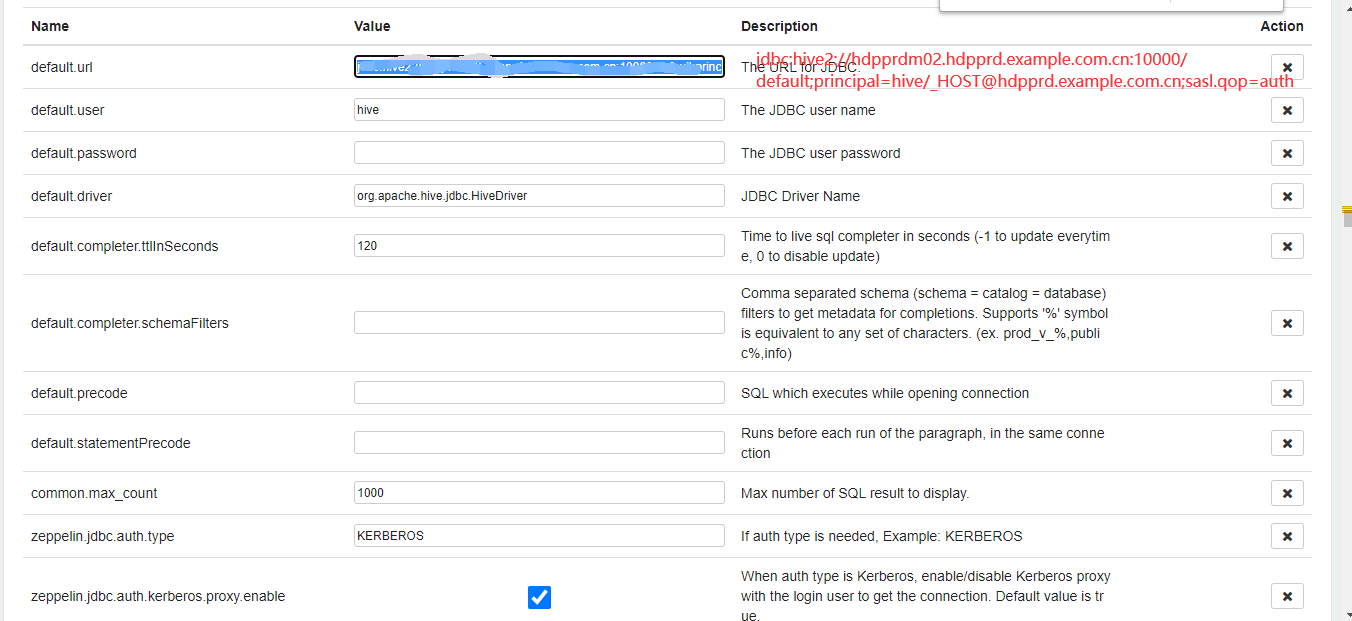
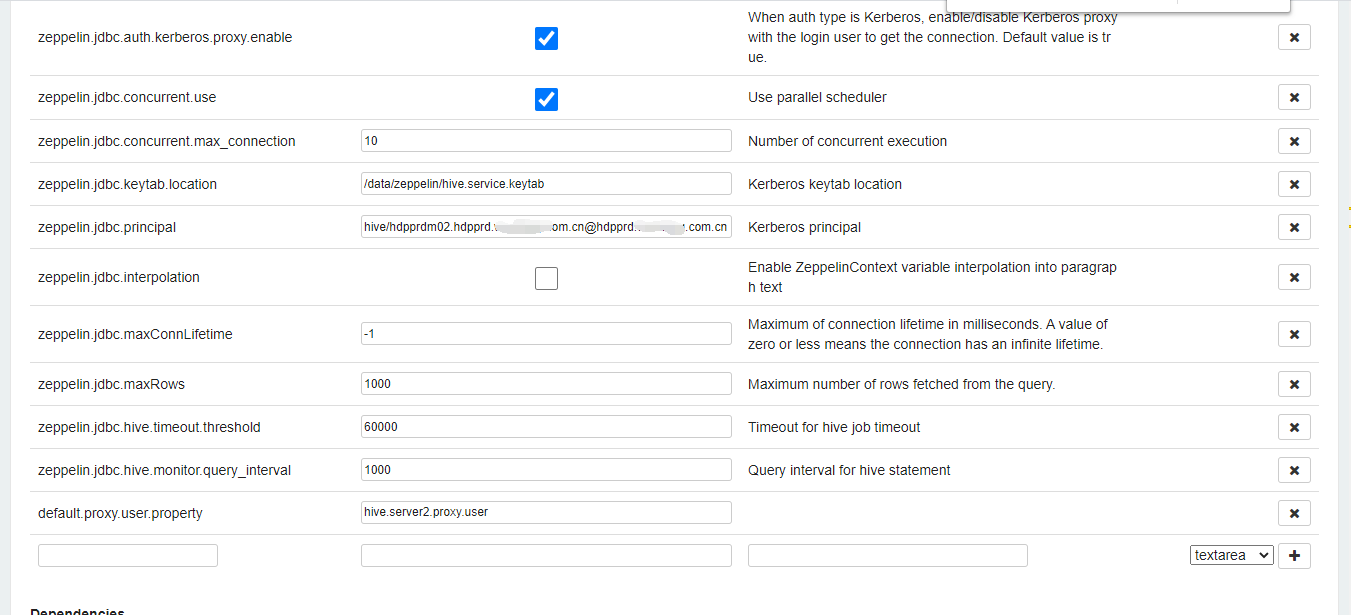
注意:需要配置依赖的jar包,我是直接把hadoop的jar和hive2的全部jar,都scp到了zeppelin-0.10.0-bin-all/interpreter/jdbc/这个目录下面,重启zeppelin, 我配置依赖出了很多问题,所以,直接暴力cp全部jar。
配置note
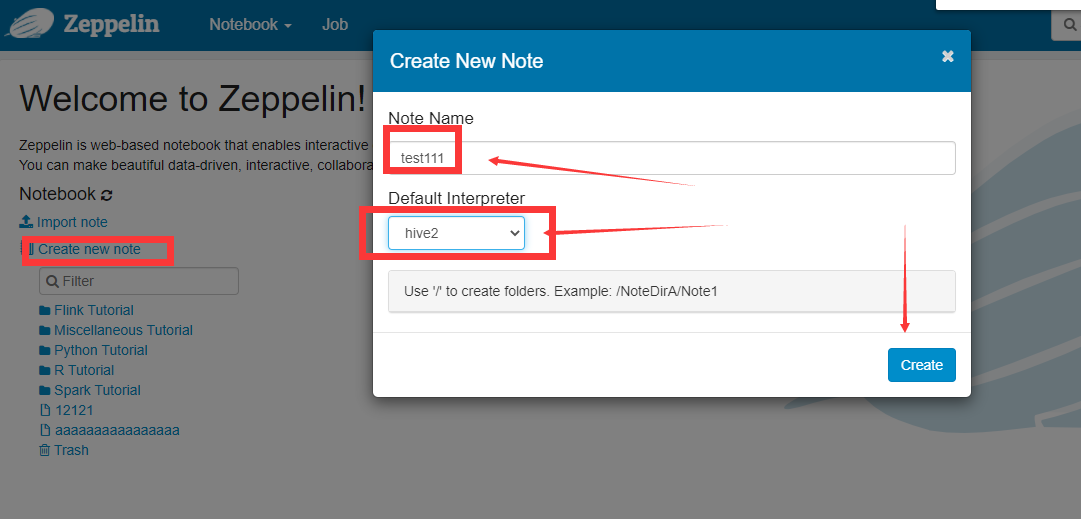
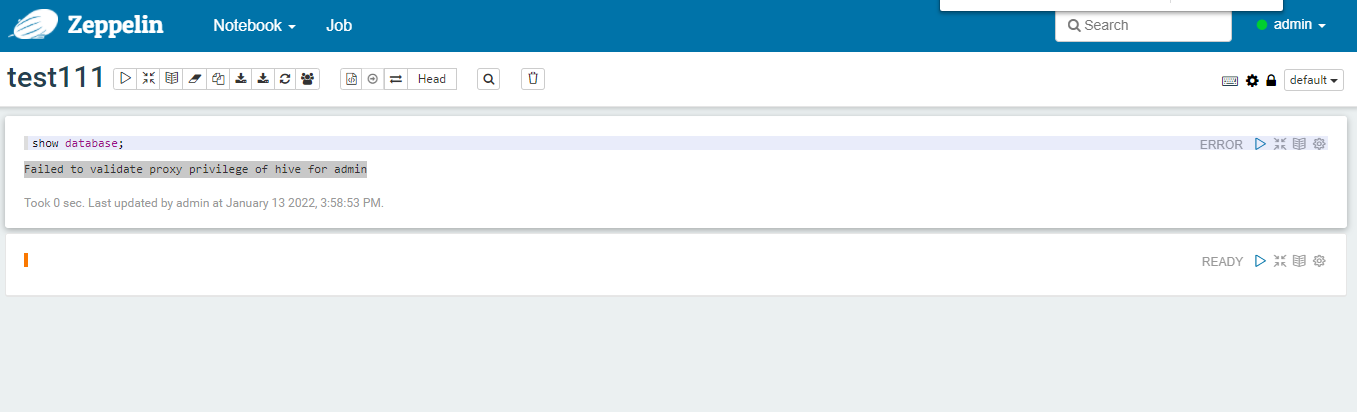
错误:Failed to validate proxy privilege of hive for admin ,这个错误是由于,我这个机器不在hdfs集群的参数(hadoop的配置文件core-site.xml)hadoop.proxyuser.hive.hosts里面。你的参数如果是,hadoop.proxyuser.hive.groups的参数也是 应该没问题(我这里是测试zeppelin,就不配置重启生产的hdfs集群了)。
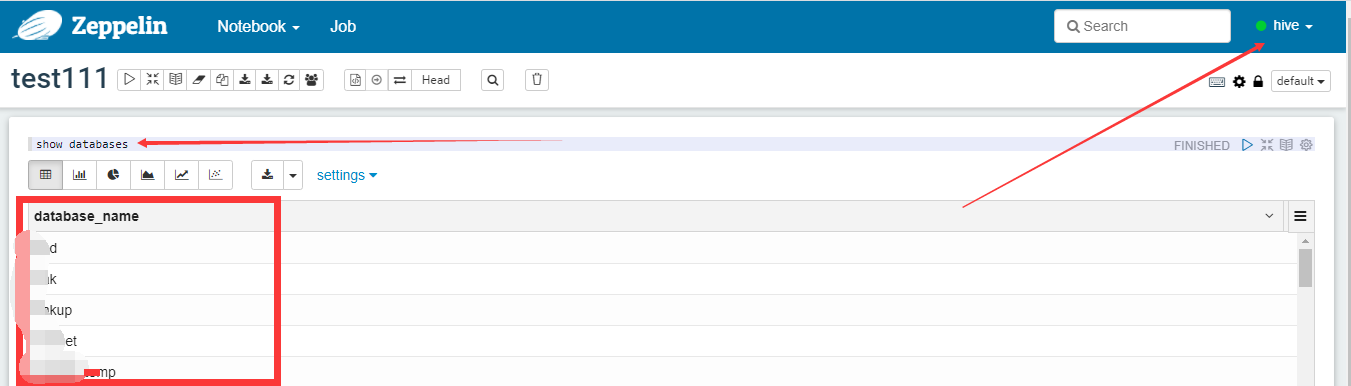
安全权限配置
安全方面包含: 1、口令登陆。2、谁有权限使用Interpreter。 3、对特定的notebook谁有读、写、运行权限。
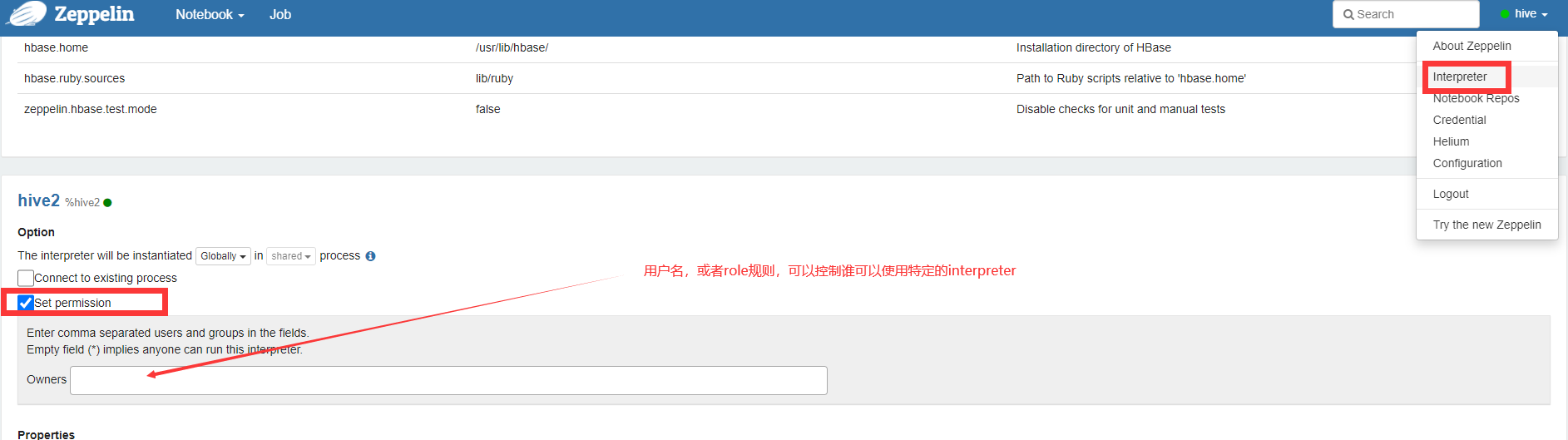
谁可以使用Interpreter
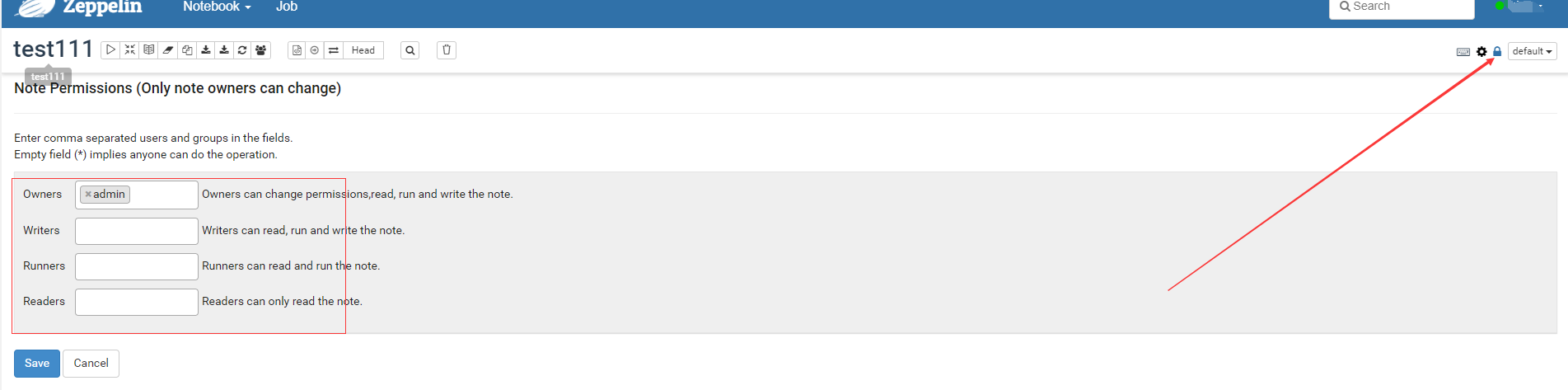
配置note谁可以读写运行
ldap整合本文不做介绍。
zeppelin flink 配置
在zeppelin 0.10 版本对Flink 1.10 or 更高版本 (Scala 2.11 & 2.12 都支持。zeppelin 0.9之前只支持Flink 1.10 Scala 2.11),经过测试对flink-1.14.2不支持,建议使用低版本flink.
下载安装 flink-1.11.6-bin-scala_2.11.tgz https://mirrors.tuna.tsinghua.edu.cn/apache/flink/
###下载flink,在zeppelin 配置flink
[root@ecs-meiyun ~]# mv flink-1.11.6-bin-scala_2.11.tgz /data/zeppelin/
[root@ecs-meiyun ~]# cd !$
cd /data/zeppelin/
[root@ecs-meiyun zeppelin]# tar xf flink-1.11.6-bin-scala_2.11.tgz
[root@ecs-meiyun zeppelin]# cd flink-1.11.6/
[root@ecs-meiyun flink-1.11.6]# pwd
/data/zeppelin/flink-1.11.6
###因为我的zeppelin 运行在zeppelin普通用户,如果你是root用户运行权限应该不会有问题。
[root@ecs-meiyun flink-1.11.6]# chown zeppelin.zeppelin -R ./
修改FLINK_HOME /data/zeppelin/flink-1.11.6 点save保存(如果你有远程的flink集群,可以不使用本地模式),配置了flink这个interpreter应该可以运行了(这是Flink的local模式,job和task 都在同一个进程里面)。
zeppelin.pyflink.python参数设置为/usr/bin/python3。因为不支持python2。确保你的机器上安装了python3 .如果你的flink不用python语言,可以不配置。
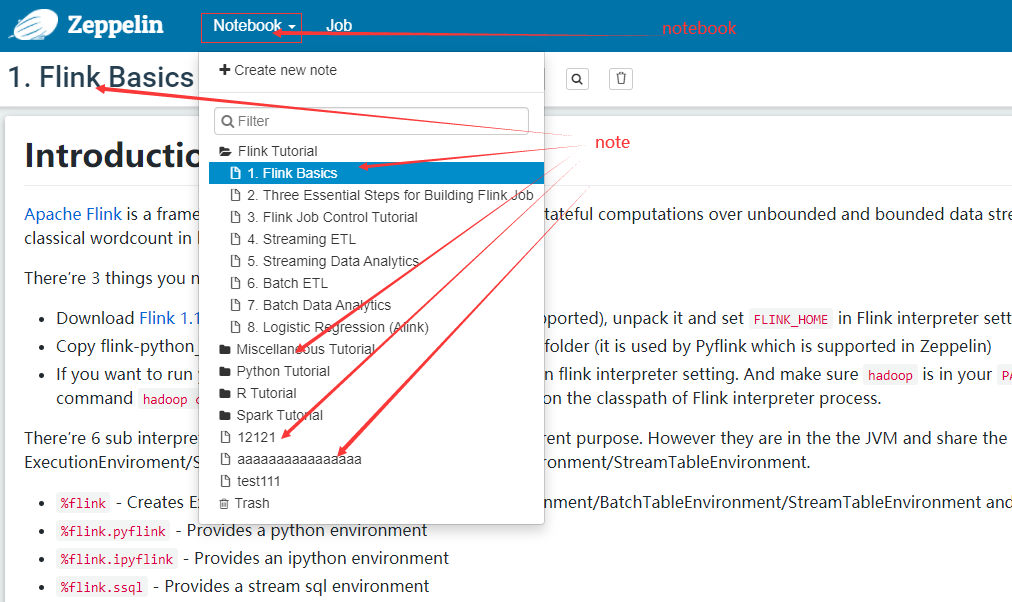
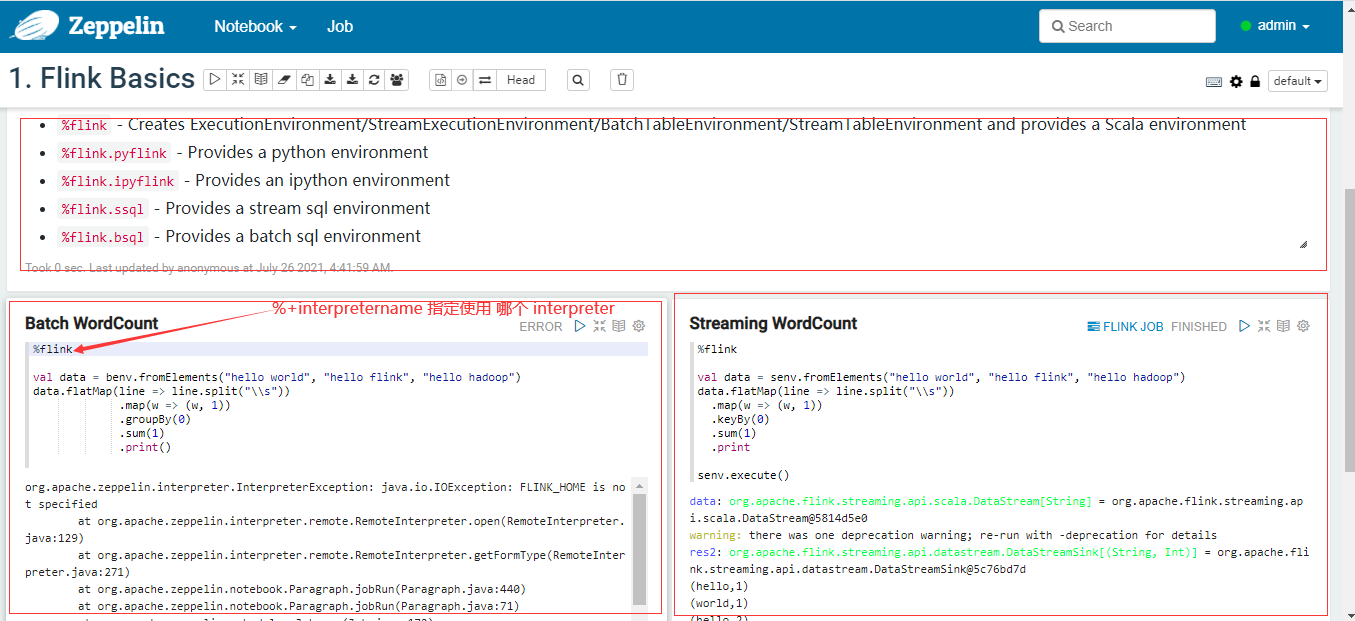
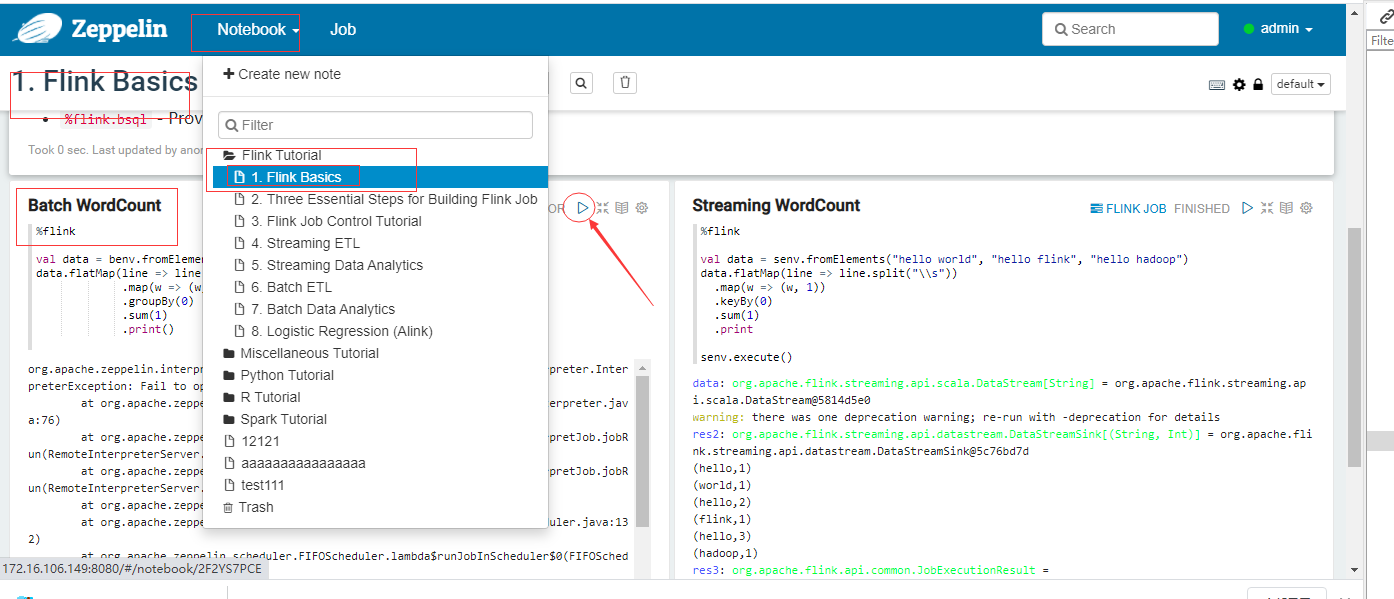
在paragraph 这个note中 运行代码,(Streaming WordCount与Batch WordCount 都可以运行了)
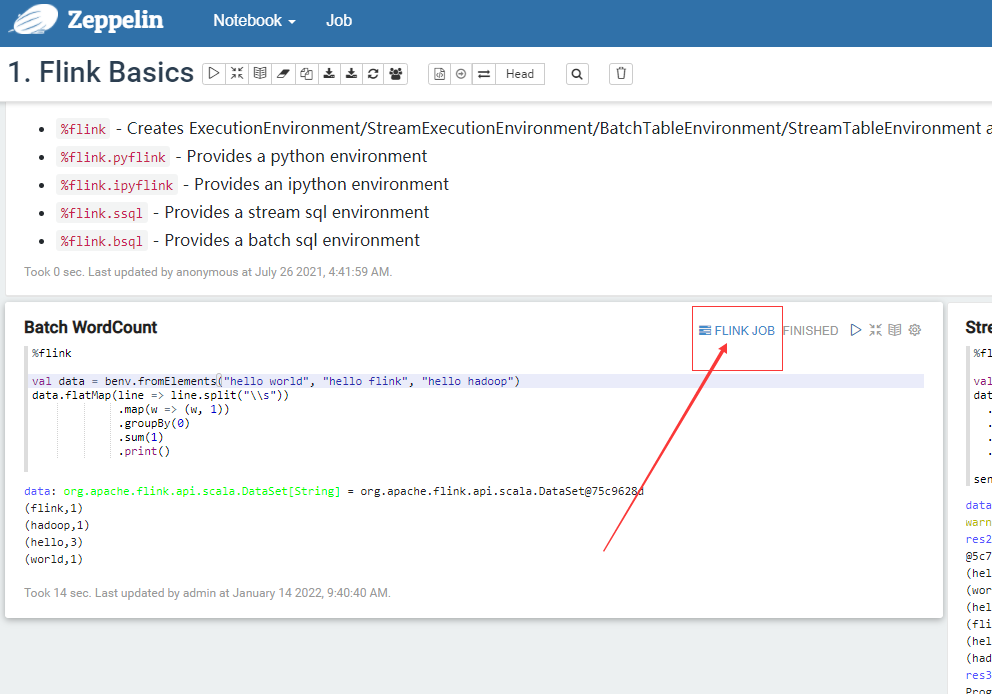
查看job 连接。 点击FLINK JOB。 进入flink的dashboard web ui界面。(注意端口冲突问题)
如果flink需要的资源较多可以修改flink的Interpreter参数 taskmanager.numberOfTaskSlots(默认1个,可以加大) 与local.number-taskmanager(默认4个,一个manager管理一个slots,4*1=4TaskSlots)参数。
查看interpreter的日志,如果flink的interpreter出现问题,排查日志:
[zeppelin@ecs-meiyun ~]$ cd /data/zeppelin/zeppelin-0.10.0-bin-all/
[zeppelin@ecs-meiyun zeppelin-0.10.0-bin-all]$ ls logs/zeppelin-interpreter-flink-shared_process-zeppelin-ecs-meiyun.hdpprd.wuzheng.com.cn.log
logs/zeppelin-interpreter-flink-shared_process-zeppelin-ecs-meiyun.hdpprd.local.com.cn.log
zeppelin对flink的语言支持。
| 支持语言 | 格式 |
|---|---|
| Scala语言 | {%flink} |
| Python语言 | {%flink.pyflink %flink.ipyflink} |
| SQL | {%flink.bsql %flink.ssql} ssql是streaming sql,bsql是batch sql |

内置变量
| zeppelin的内置变量 |
|---|
| benv |
| senv |
| btenv(bt_env) |
| stenv(st_env) |
| btenv_2(bt_env_2) |
| stenv_2(st_env_2) |
| z |
连接远程flink standalone 集群
除了指定flink.execution.modebe外remote,还需要指定 flink.execution.remote.hostandflink.execution.remote.port指向 Flink 作业管理器的 rest api 地址。
##重启zeppelin,关闭本地local模式flink
[zeppelin@ecs-meiyun zeppelin-0.10.0-bin-all]$ ./bin/zeppelin-daemon.sh restart
#启动flink 集群
[zeppelin@ecs-meiyun flink-1.11.6]$ ./bin/start-cluster.sh
Starting taskexecutor daemon on host ecs-meiyun.hdpprd.wuzheng.com.cn.
[zeppelin@ecs-meiyun flink-1.11.6]$ netstat -tunlp | grep 8081
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 :::8081 :::* LISTEN 20697/java
配置interpreter并保存
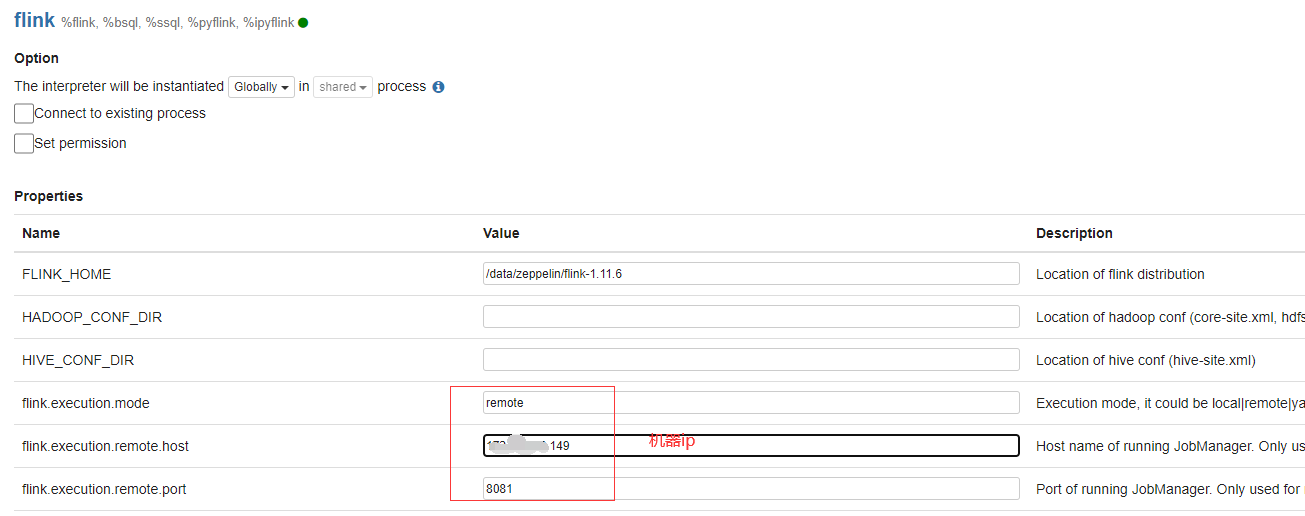
可以再次运行batch wordcount 这个代码。
yarn模式,Flink in Yarn mode
Set flink.execution.mode to be yarn Set HADOOP_CONF_DIR in Flink's interpreter setting or zeppelin-env.sh. Make sure hadoop command is on your PATH. Because internally Flink will call command hadoop classpath and load all the hadoop related jars in the Flink interpreter process
Yarn Application Mode模式
Set flink.execution.mode to be yarn-application Set HADOOP_CONF_DIR in Flink's interpreter setting or zeppelin-env.sh. Make sure hadoop command is on your PATH. Because internally flink will call command hadoop classpath and load all the hadoop related jars in Flink interpreter process