hadoop3.0
访问量:2884
创建时间:2021-05-24
hadoop组成
Hadoop是一个有Apache基金会所开发的分布式系统基础架构。主要解决,海量数据的存储和分析计算问题。广义上hadoop通常是指一个更广泛的概念--hadoop生态圈。
hadoop1.x 2.x 3.x区别
| 版本 | 组成 |
|---|---|
| hadoop1.x | Common(辅助工具),hdfs数据存储,mapreduce计算+资源调度 |
| hadoop2.x | Common(辅助工具),hdfs数据存储,Mapreduce计算,Yarn资源调度 |
| hadoop3.x | 组成无区别,增加了新特性 |
HDFS概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
| 组件 | 作用 |
|---|---|
| namenode(nn) | 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的datanode等。 |
| datanode(dn) | 在本地文件系统存储文件快数据,以及块数据的校验和。 |
| Secondary Namenode(2nn) | 每隔一段时间对NameNode元数据备份 |
yarn架构概述
YetAnother Resource Negotiator 简称Yarn,另一种资源协调者,是hadoop的资源管理器。
| yarn组件 | 作用 |
|---|---|
| Resource Manager(RM) | 管理整个集群所有的内存cpu资源, |
| NodeManager(NM) | 管理每台服务器的内存cpu资源, |
| ApplicationMaster(AM) | 单个任务运行的管理 |
| Container | 容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、cpu、磁盘、网络等。AM与maptask、reducetask运行于container中。 |
集群上可以运行多个AM,每个nodemanager上可以有多个container.
MapReduce架构
MapReduce将计算过程分为两阶段:Map和Reduce,Map阶段并行处理输入数据,Reduce阶段对Map结果进行汇总。
大数据技术生态体系
| 数据来源层 | 数据特点 |
|---|---|
| 数据库 | 结构化数据 |
| 文件日志 | 半结构化数据 |
| 视频、ppt等 | 非结构化数据 |
| 数据传输层 | 作用 |
|---|---|
| Sqoop数据传递 | 同步结构化数据(数据库) |
| Flume日志收集 | 收集半结构化数据,文件日志 |
| Kafka消息队列 | 结构化、半结构化、非结构化 |
| 数据存储层 |
|---|
| hdfs文件存储 |
| hbase非关系型数据库 |
| kafka消息队列 |
| 资源管理层 |
|---|
| YARN |
| 数据计算层(离线) | 下一层 |
|---|---|
| mapreduce离线计算 | Hive sql数据查询 |
| Spark Core内存计算 | SparkMlib数据挖掘、Spark Sql数据查询 |
| 数据计算层(实时计算、流计算) |
|---|
| storm实时计算(老项目可能还在用) |
| spark streaming实时计算 |
| Flink内存计算框架、实时场景使用较多 |
| 调度任务层(调度器) |
|---|
| oozie |
| azkaban |
| airflow |
| 其他自开发、开源组件 |
| 业务模型层 |
|---|
| 业务模型 |
| 数据可视化 |
| 业务应用 |
HDFS组织结构
| 优点 | 缺点 |
|---|---|
| 高容错、数据多副本,副本丢失自动恢复 | 不适合低延迟的数据访问,比如毫秒级的数据存储 |
| 适合处理大数据,GB\TB\PB,能够处理百万规模以上的文件数量。 | 无法高效的对大量小文件进行存储,会占用namenode大量内存,小文件存储的寻址时间会超过读取时间。 |
| 可以构建在廉价的机器上 | 不支持并发写入、文件随即修改,一个文件只能有一个写,不允许多线程同时写入。仅支持数据append追加,不支持文件随即修改。 |
| HDFS架构 |
|---|
| NameNode,集群管理者,管理hdfs命名空间;配置副本策略;管理数据块映射信息;处理客户端读写请求。 |
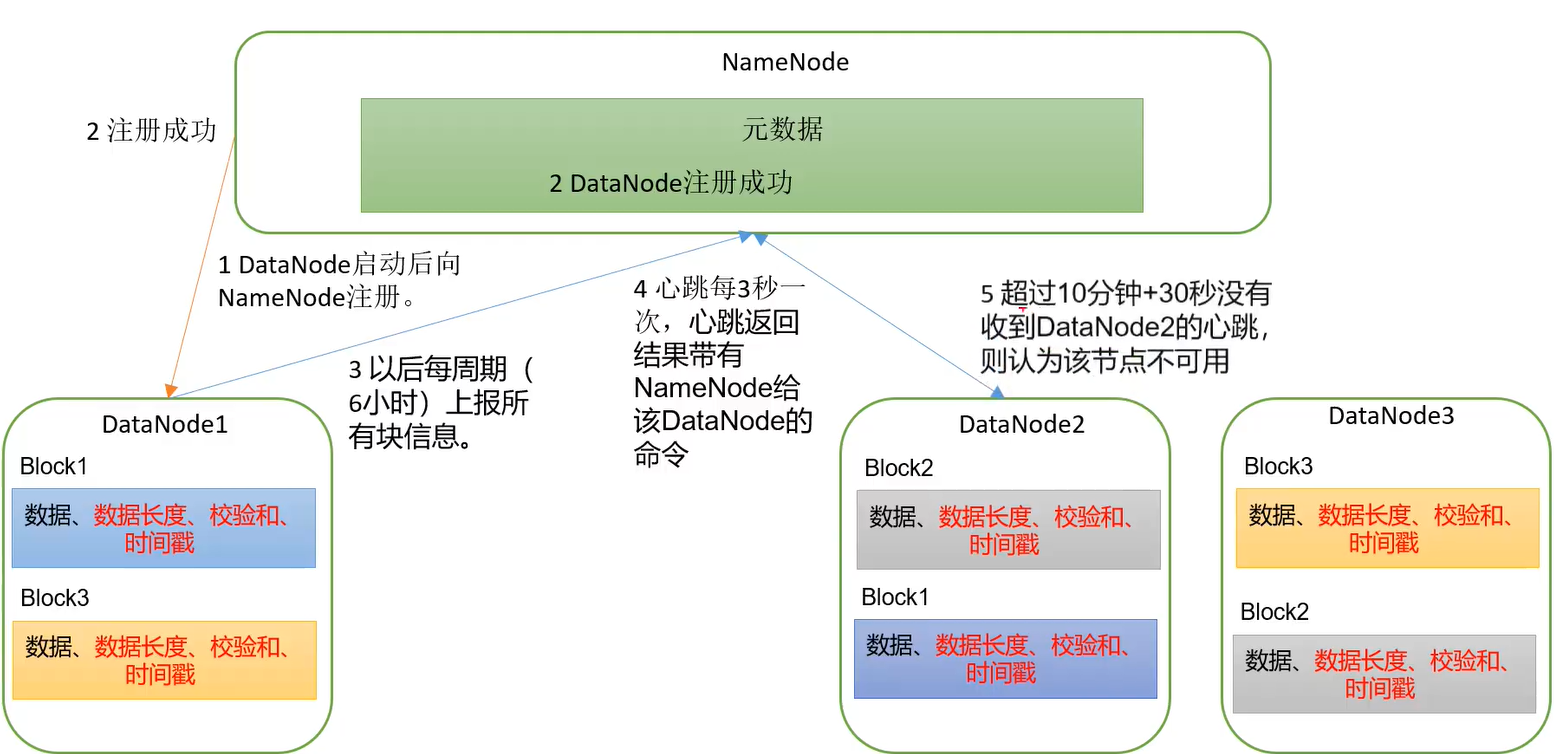
| DataNode:存储实际的数据块;执行数据块的读写操作。 |
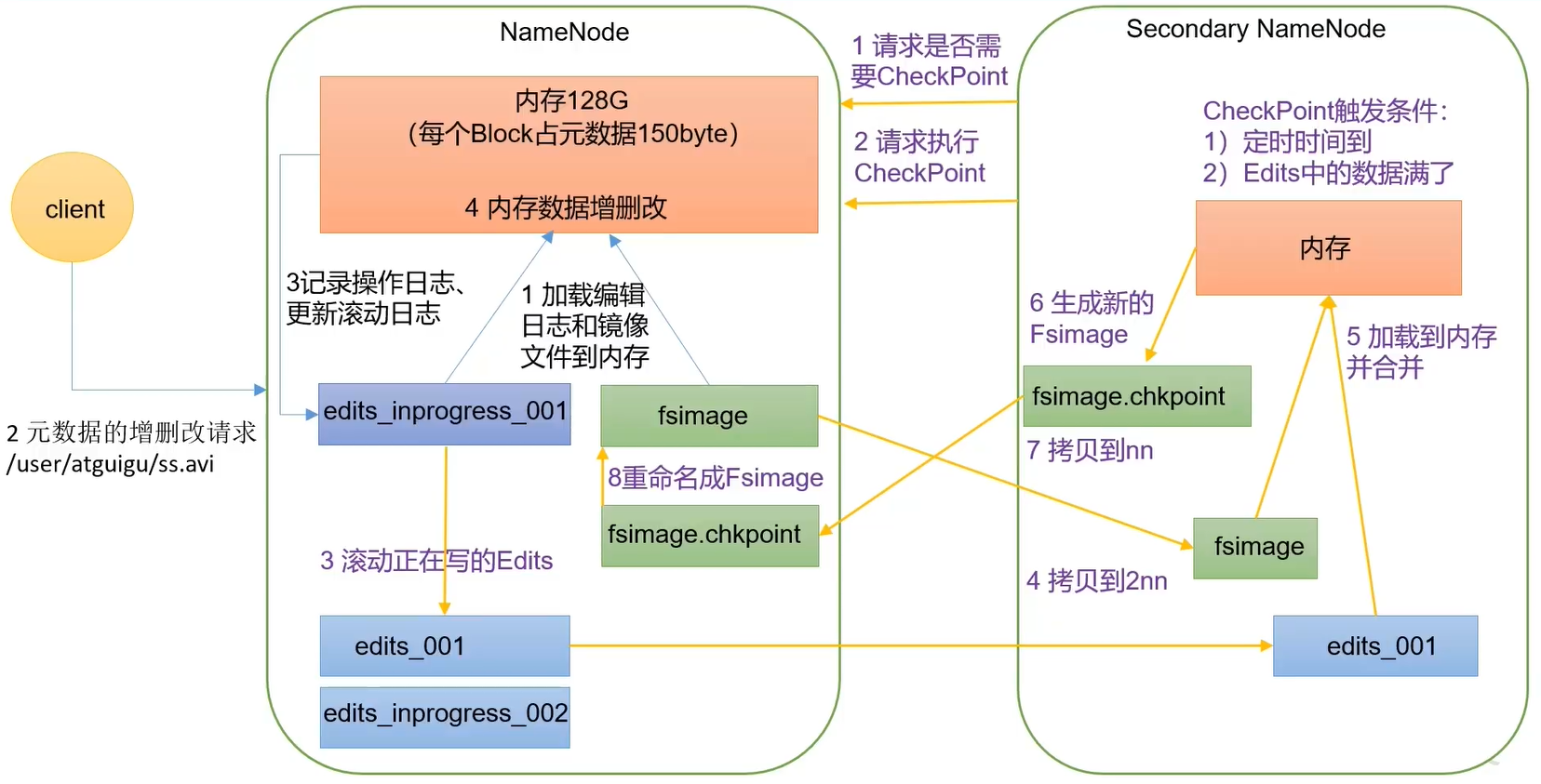
| SecondaryNameNode:并非NameNode的热备。当NameNode挂了,它不能马上替换Namenode并提供服务。辅助NameNode,分担工作量,比如定期合并Fsimage和Edits,并推送给NameNode;在紧急情况下,可辅助恢复NameNode |
| Client客户端,文件切分。文件上传HDFS时,client将文件切分成一个一个的文件块。与NameNode交互获取文件位置信息;与DataNode校核,读取写入数据;client提供一些命令来管理HDFS比如hdfs格式化;client可以通过一些命令来访问hdfs,比如对hdfs增删改查操作 |
HDFS的文件在物理上时分块存储Block,块大小可以通过配置参数dfs.blocksize来规定,默认大小在hadoop2.x/3/x是128M,1.x版本是64M。如果寻址时间约为10ms,即查找到目标block的时间为10ms.寻址时间为传输时间的1%时,为最佳状态,因此传输时间=10ms/0.01=1s ,1s*100MB/s=100MB.而目前机械磁盘的传输速率普遍为100MB/s。(机械硬盘块大小可以设置128M,固态可以设置256M); hdfs块设置太小,一个文件块数多,会增加寻址时间,程序一直在找块的开始位置。如果设置块太大,从磁盘传输数据的时间会明显大于定位块位置时间。导致程序处理数据块会非常慢,不利于后期运算。HDFS块大小设置主要取决于磁盘传输速率。
常用命令(省略)
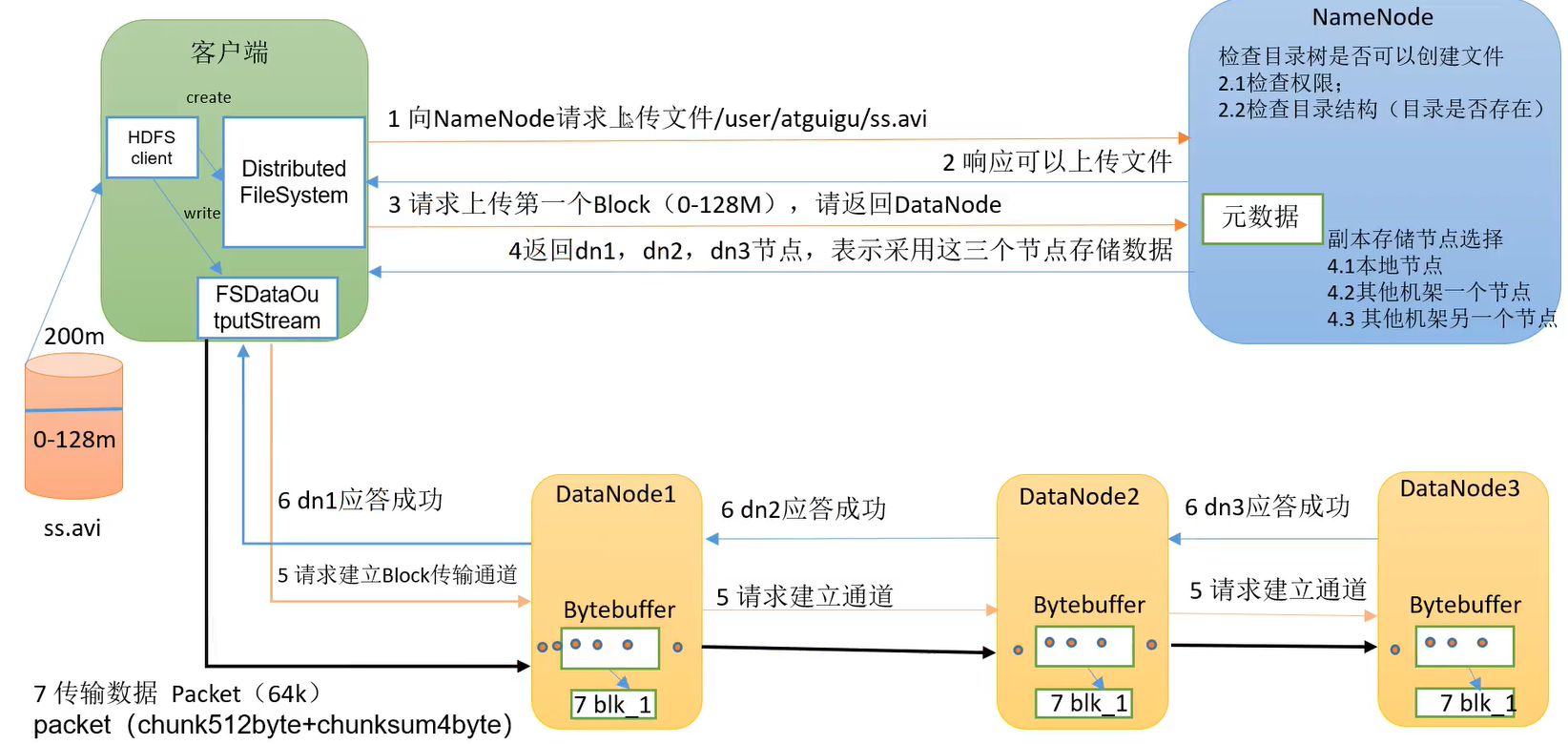
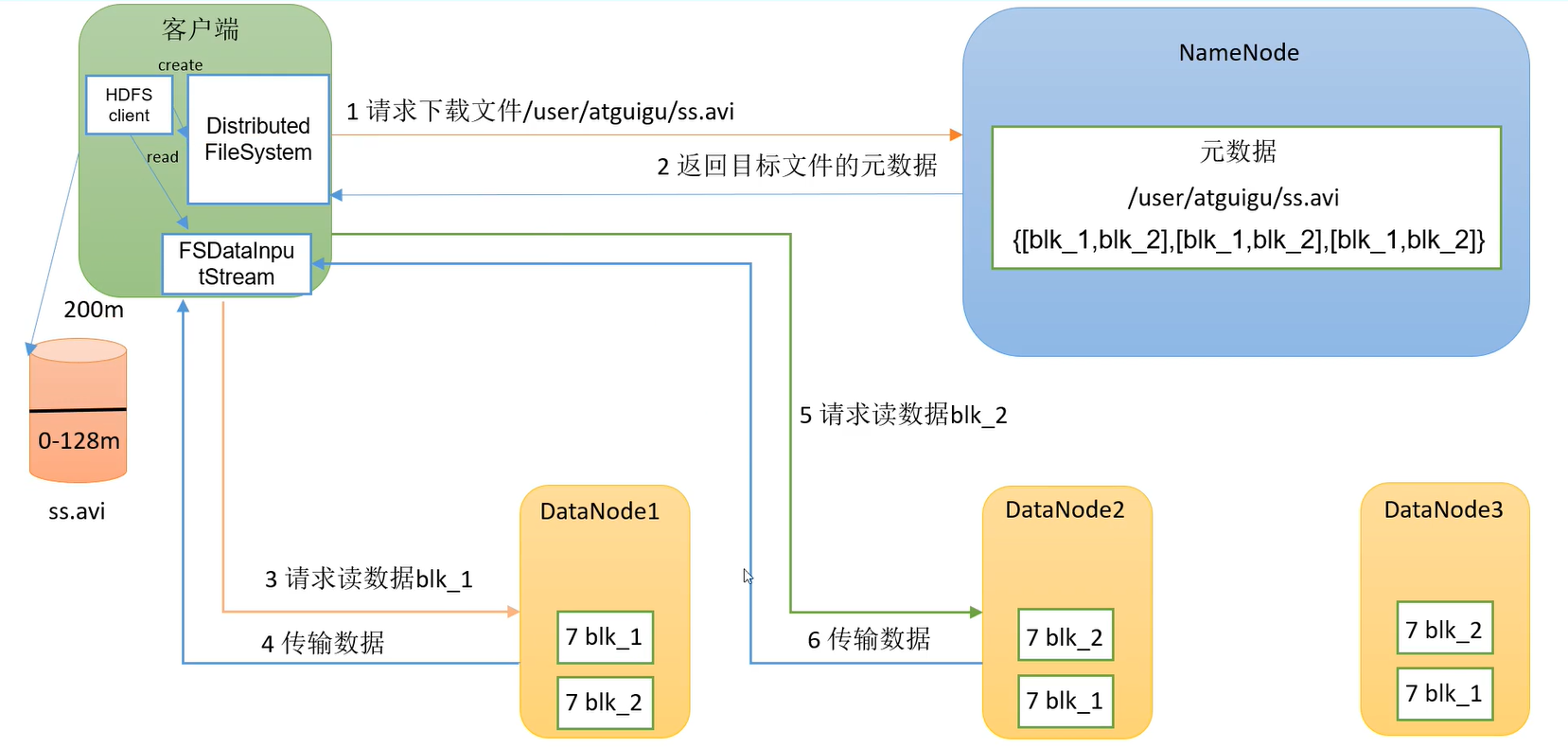
HDFS读写流程
NameNode工作机制
datanode 工作机制
参考视频:https://www.bilibili.com/video/BV1Qp4y1n7EN
登陆评论:
使用GITHUB登陆