mysql 5.5 基础 高级 优化
参考资料,侵权请联系我删除: https://wwtianmei.cn/2020/12/31/mysql-zong-he-lian-xi/ https://www.bilibili.com/video/BV15t4y1Y73N
select查询
这里下载的5.5.62,windows 64-bit MSI 包,安装过程Typical 典型安装,custom 自定义安装,complete 完全安装,通过3种模式来决定安装哪些组件,选Typical即可。 安装之后需要进行配置,如下图所示,具体配置过程省略。
图形化客户端可以使用HeidiSQL
创建测试数据
-- 创建部门表
DROP TABLE IF EXISTS dept;
CREATE TABLE dept(
-- 部门编号
deptno int PRIMARY KEY,
-- 部门名称
dname VARCHAR(14),
-- 部门所在地
loc VARCHAR(13)
);
-- 向部门表插入数据
INSERT INTO dept VALUES (10,'ACCOUNTING','NEW YORK');
INSERT INTO dept VALUES (20,'RESEARCH','DALLAS');
INSERT INTO dept VALUES (30,'SALES','CHICAGO');
INSERT INTO dept VALUES (40,'OPERATIONS','BOSTON');
-- 创建员工表
DROP TABLE IF EXISTS emp;
CREATE TABLE emp(
-- 员工编号
empno int PRIMARY KEY,
-- 员工姓名
ename VARCHAR(10),
-- 工作岗位
job VARCHAR(9),
-- 直属领导
mgr int,
-- 入职时间
hiredate DATE,
-- 工资
sal double,
-- 奖金
comm double,
-- 所属部门
deptno int
);
-- 为员工表表添加外键约束
ALTER TABLE emp ADD CONSTRAINT FOREIGN KEY EMP(deptno) REFERENCES dept (deptno);
-- 向员工表插入数据
INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,"1980-12-17",800,NULL,20);
INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,'1987-07-03',3000,NULL,20);
INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,'1987-07-13',1100,NULL,20);
INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,'1981-01-23',1300,NULL,10);
-- 创建工资等级表
DROP TABLE IF EXISTS salgrade;
CREATE TABLE salgrade(
-- 等级
grade int,
-- 最低工资
losal double,
-- 最高工资
hisal double
);
-- 向工资等级表插入数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
简单的select 查询
查询年薪sal * 12
select ename , sal * 12 `annule sal` from emp;
查询总薪水sal * 12 + comm,comm 津贴
select ename,sal * 12 + (case when comm is NULL then 0 else comm end) as annual_sal from emp;
查询部门编号为30的部门的员工详细信息
SELECT * FROM emp WHERE deptno = 30;
查询部门编号不等于30的部门的员工详细信息
SELECT * FROM emp WHERE deptno <> 30;
查询从事clerk工作的员工的编号、姓名以及其部门号
SELECT empno,ename,deptno FROM emp WHERE job = 'clerk';
查询奖金多于基本工资的员工的信息
SELECT * FROM emp WHERE comm > sal;
查询奖金多于基本工资60%的员工的信息
SELECT * FROM emp WHERE comm > sal * 0.6;
查询部门编号为10的部门经理和部门编号为20的部门中工作为CLERK的职员信息
SELECT * FROM emp WHERE deptno = 10 AND job='MANAGER' OR deptno = 20 AND job = 'CLERK';
查询部门编号为10的部门经理或部门编号为20的部门工作为CLERK的职员信息或者既不是经理也不是CLERK但是工资高于2000的员工信息
SELECT * FROM emp WHERE deptno = 10 AND job='MANAGER' OR deptno = 20 AND job = 'CLERK' OR job NOT IN ('MANAGER','CLERK') AND sal > 2000 ;
查询获得奖金的员工的信息
SELECT * FROM emp WHERE comm > 0 and comm is not null;
查询奖金少于100或者没有获得奖金的员工的信息
SELECT * FROM emp WHERE comm < 100 OR comm IS NULL;
查询姓名以A、B、S开头的员工的信息(LIKE 模糊查询)
SELECT * FROM emp WHERE ename LIKE 'A%' OR ename LIKE 'B%' OR ename LIKE 'S%';
查询找到姓名长度为6个字符的员工的信息
SELECT * FROM emp WHERE LENGTH(ename) = 6;
查询姓名中不包含R字符的员工信息。
SELECT * FROM emp WHERE ename NOT LIKE '%R%';
查询员工的详细信息并按姓名排序
SELECT * FROM emp ORDER BY ename ASC;
查询员工的信息并按工作降序工资升序排列
SELECT * FROM emp ORDER BY job DESC , sal ASC;
计算员工的日薪(按30天计)
SELECT ename,sal/30 AS '日薪' FROM emp;
查询姓名中包含字符A的员工的信息
SELECT * FROM emp WHERE ename LIKE ''%A%';
查询拥有员工的部门的部门名和部门号(DISTINCT去重)
SELECT DISTINCT d.dname, d.deptno FROM dept d,emp e WHERE d.deptno = e.deptno;
Select DISTINCT d.deptno,d.dname from emp e, dept d where e.JOB IS NOT NULL;
查询工资多于smith的员工信息。
SELECT *FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename = 'smith');
函数转小写
select lower('AAA');
函数连接字符串
select concat('a','b','c') as alls;
函数字符串长度
select char_length('aaa');
取当前时间的函数
select curdate();
select curtime();
select now();
select ename,hiredate from emp order by year(hiredate);
组函数
select max(sal) from emp;
select ename from emp where sal = (select max(sal) from emp);
select min(sal) from emp;
select avg(sal) from emp;
#count如果只有一个字段,NULL空值不计数
select count(comm) from emp;
分组group by 可以跟多个条件group by deptno,job
select max(sal) from emp group by deptno;
取出平均薪水,按deptno分组,having子句可以让我们筛选成组后的各组数据,筛选AVG(sal)大于2000的
SELECT AVG(sal) FROM emp GROUP BY deptno HAVING AVG(sal) > 2000;
#select总结
where xxx 对数据进行过滤
group by ;分组
having; 对分组进行限制
order by ; 排序
SELECT AVG(sal) FROM emp WHERE sal > 1200 GROUP BY deptno HAVING AVG(sal) > 1500 ORDER by avg(sal) DESC;
子查询,一个select嵌套另一个select
--哪些人的工资比平均工资高
SELECT ename,sal from emp where sal > (SELECT AVG(sal) FROM emp)
-- 按照部门分组后,每个部门工资最高的人(可能多个),显示部门、名字、编号
SELECT ename,sal FROM emp join (SELECT MAX(sal) max_sal,deptno FROM emp GROUP BY deptno) t ON (emp.sal = t.max_sal AND emp.deptno = t.deptno)
-- 自连接
-- 运用一条select语句,查询出一个人的名字和他所在的部门经理的名字
SELECT e1.ename emp,e2.ename mgr FROM emp e1, emp e2 WHERE e1.mgr = e2.empno
-- 左外连接,将左边表的多余数据显示出来(KING,NULL)
SELECT e1.ename emp ,e2.ename mgr FROM emp e1 left join emp e2 on e1.mgr = e2.empno
-- 表连接
-- SQL1992语法
SELECT ename,dname FROM emp,dept WHERE emp.deptno = dept.deptno
-- SQL1999语法
SELECT e.ename,d.dname FROM emp e join dept d on e.deptno = d.deptno
-- 取人名、部门名称、薪水等级(sal位于等级范围之内)
-- 1992
SELECT e.ename,d.dname , s.grade FROM emp e , dept d,salgrade s WHERE e.deptno = d.deptno AND e.sal >= s.losal AND e.sal <= s.hisal;
-- 1999
SELECT e.ename,d.dname,s.grade
FROM emp e
JOIN dept d ON (e.deptno= d.deptno)
JOIN salgrade s ON (e.sal BETWEEN s.losal AND s.hisal);
-- 部门平均薪水的等级
SELECT a.grade,b.sal_avg,b.deptno from salgrade a JOIN ( SELECT AVG(sal) AS sal_avg,deptno FROM emp GROUP BY deptno ) b ON (b.sal_avg >= a.losal AND b.sal_avg <= a.hisal)
-- 部门平均的薪水等级
SELECT AVG(grade),deptno FROM emp e JOIN salgrade s ON (e.sal >= s.losal AND e.sal<= s.hisal) GROUP BY deptno
-- 哪些人是经理
SELECT * FROM emp e JOIN (SELECT DISTINCT mgr FROM emp) b ON e.empno = b.mgr;
SELECT * FROM emp e where e.empno in (SELECT DISTINCT mgr FROM emp) ;
-- 不用组函数求最高薪水
SELECT sal FROM emp WHERE sal NOT IN (SELECT distinct e1.sal FROM emp e1 JOIN emp e2 ON (e1.sal < e2.sal))
-- 平均薪水最高的部门编号与名称
SELECT dname FROM dept WHERE deptno = (
SELECT deptno FROM
(SELECT AVG(sal) avg_sal,deptno FROM emp GROUP BY deptno) t1
WHERE avg_sal =
(SELECT MAX(avg_sal) FROM
(SELECT AVG(sal) avg_sal , deptno FROM emp GROUP BY deptno) t2
)
);
#####使用视图
CREATE VIEW v1 as SELECT AVG(sal) avg_sal , deptno FROM emp GROUP BY deptno
SELECT dname FROM dept WHERE deptno = (
SELECT deptno FROM v1
WHERE avg_sal = (SELECT MAX(avg_sal) FROM v1)
);
-- 比 普通员工的最高薪水还要高的经理人名称
SELECT ename FROM emp
WHERE empno IN ( SELECT DISTINCT mgr FROM emp WHERE mgr IS NOT NULL)
AND sal >
(SELECT MAX(sal) FROM emp WHERE empno NOT IN (SELECT DISTINCT mgr FROM emp WHERE mgr IS NOT NULL));
分页
oracle:
select ename,sal from (select ename,sal from emp order by sal desc) where rownum <=5;
mysql:
select ename,sal from emp limit 5;
select ename,sal from emp limit 5,5 ;
select ename,sal from emp limit 10,5 ;
DDL语句
主键自增 id 联合主键 多个字段作为主键 非空约束 不为null,不能插入null的数据 唯一约束 unique 不能有重复,例如email 默认值 外键约束 foreign key 插入数据时参考其他表,其他表没有对应数据就插不进去。
DML语句
crud = insert select update delete
insert into xx values ()
insert into c1,c2 values (x1,x2)
update xx set xx=xx,xx=xx where xx
delete from xx where xx
索引
索引相当于书(字典)的目录
mysql 常用索引B+tree 和hash,默认是前者( mysql的 innodb 引擎只支持btree,不支持hash)
创建删除索引
create index idx_email on student(email)
drop index idx_email on student
create index idx_email using hash on student(email) #还是btree
mysql索引为什么是b+tree
| 数据结构 | 特点 |
|---|---|
| 哈希表 | 等值查询很快(memory引擎使用hash),innodb 支持自适应hash ;1. hash冲突会造成数据散列不均匀,会产生大量线性查询。2.不支持范围查询,范围查询需要遍历。3.对内存要求比较高 |
| 二叉树 | 每个节点有切仅有2个分支,数据无序 |
| BST | binary search tree,插入数据有序,左子<根<右子,有序可以使用二分查找提高速度(速度从O(n)到O(logn));递增或者递减插入,会退化成链表,查询速度变回On,需要让树保持平衡 |
| AVL | 经过左旋或者右旋(最短子树跟长子树高度之差不能超过1) 让树平衡,avl是平衡二叉树,为了保持平衡,插入时需要旋转,通过插入损失性能弥补查询时的性能损失。(对写少读多场景较好) |
| 红黑树 | (如果读写请求一样的场景)红黑树需要左旋、右旋让树平衡,还有变色行为,最长子树只要不超过最短子树2倍即可;缺点树越深,io次数越多(原因每个节点有且仅有2个分支) |
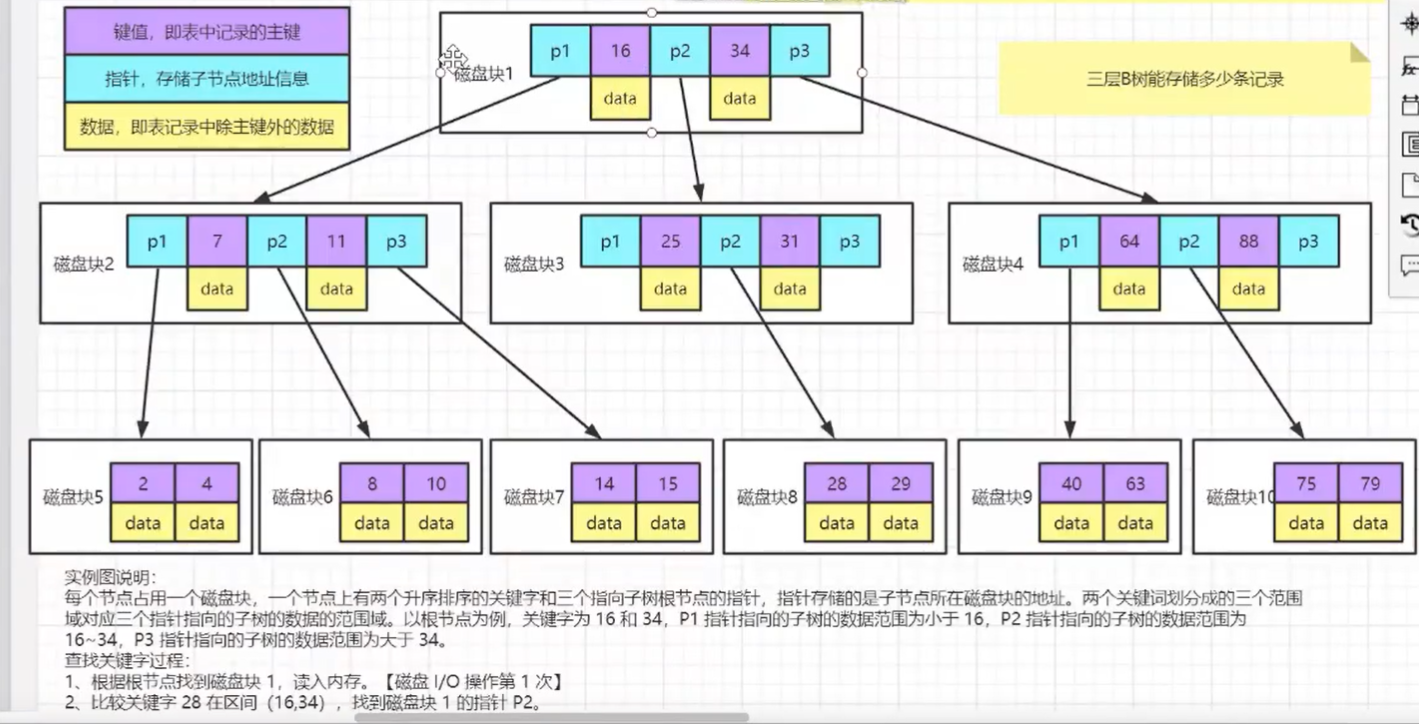
| B树 | 把有序二叉树变为有序多叉树,degree=n每个节点放n-1条记录 |
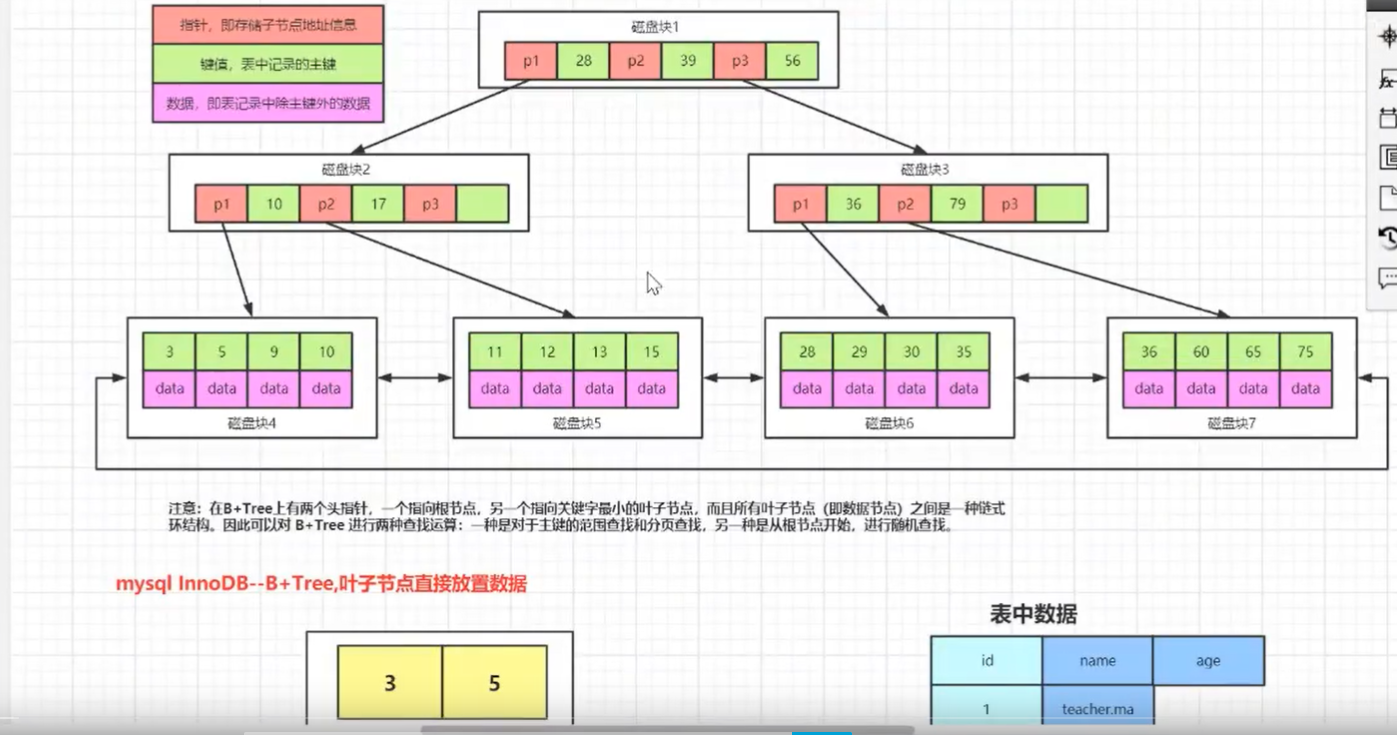
| B+树 | 非叶子节点不存储数据。叶子结点存储数据,3层B+数存放数据量比B数多很多(指针大小固定,key值占用空间越小[int的索引与字符串索引的区别,int会占用空间小,字符串索引的key大小比较与ASCII码比大小一样,挨个比]1个16K的块可存储数据量越多),叶子结点是双向链表,每个节点的degree是根据指针与key的大小决定的。 |
btree实际存储数据时怎么存储?(k,v) 完整的数据行
btree
- b+tree
索引的创建与存储引擎挂钩,存储引擎表示不同的数据在磁盘的不同的组织结构。
表.frm 存储表结构 表.ibd 存储索引与数据(ibd是innodb引擎,innodb只能有一个聚簇索引【但是有很多非聚簇索引索引】,向innodb插入数据必须包含一个索引的key值,如果建表时不创建索引,key就是主键,没有主键就是唯一键,没有唯一键就是自生成【用户不可见】的6字节的rowid)
columns_priv.frm columns_priv.MYD 存储data columns_priv.MYI 表示索引(myisam引擎)
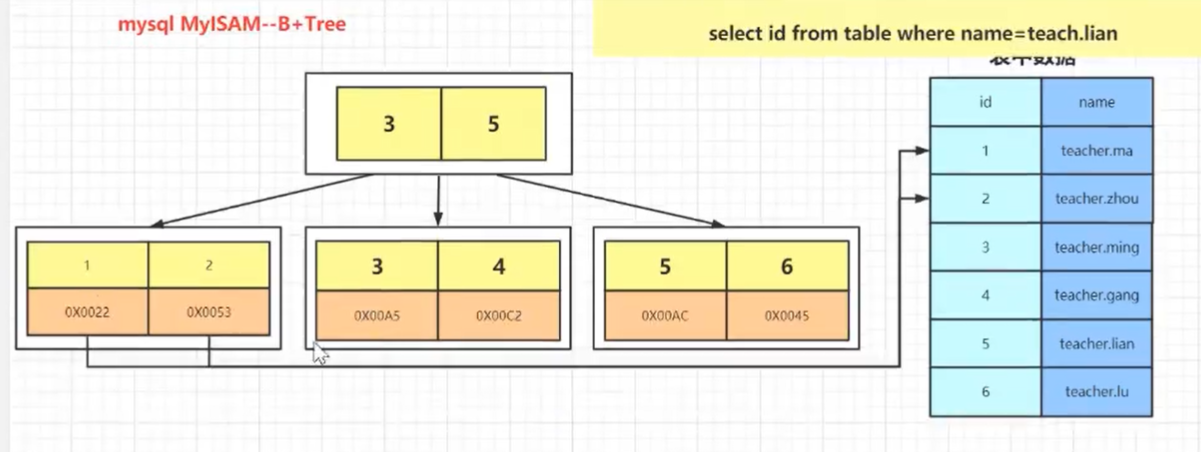
聚簇索引 是否是聚簇索引取决于数据与索引是否放在一起。 非聚簇索引 myisam
数据库中B+树索引分为聚集索引(clustered index)和非聚集索引(secondary index).这两种索引的共同点是内部都是B+树,高度都是平衡的,叶节点存放着所有数据。不同点是叶节点是否存放着一整行数据。
(1) 聚集索引-聚簇索引 Innodb存储引擎表是索引组织表,即表中数据按主键顺序存放。而聚集索引就是按每张表的主键构造一颗B+树。并且叶节点存放整张表的行记录数据。每张表只能有一个聚集索引(一个主键)。 聚集索引的另一个好处是它对于主键的排序查找和范围的速度非常快。叶节点的数据就是我们要找的数据。
(2) 辅助索引-非聚簇索引 辅助索引(也称非聚集索引)。叶级别不包含行的全部数据, 辅助索引的存在并不影响数据再聚集索引中的组织,因此一个表可以有多个辅助索引。当通过辅助索引查找数据时,innodb会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键。然后再通过主键索引找到一行完整的数据。
| 存储引擎 | 索引类型 | 主键叶子节点 | 非主键叶子节点 |
|---|---|---|---|
| MyISAM | 非聚簇 | 数据地址 | 数据地址 |
| InnoDB | 聚簇 | 全部数据 | 主键值 |
| key重复 | 不能 | 能 |
注意: Innodb b+tree 如果创建索引的建是其他字段,那么在子叶节点中存储的是该记录的主键,然后在通过主键索引找到对应的记录,叫做回表。
1、mysql表中至少一个索引 2、回表 3、索引覆盖 4、最左匹配 5、索引下推
假设有1张表,有id name age gender 4个字段,id是主键,name是索引列(一共2个索引列)。
回表
select * from table name=zhangsan 执行这个sql时使用name作为索引,找到id,再根据id查询找到整个记录,走了2颗b+tree,这种现象叫做回表。当根据普通索引查询到聚簇索引的key值后,再根据key值在聚簇索引中找到整行记录
索引覆盖
select id,name from table name=zhangsan 这次查询可以根据name直接查询到id和name的值,直接返回,不需要从查找聚簇索引查找数据,叫做索引覆盖,比回表效率高。
最左匹配
主键--联合主键(2个列) 索引--联合索引(2个列) --组合索引 (可能包含多个索引列),组合索引key值有2个值
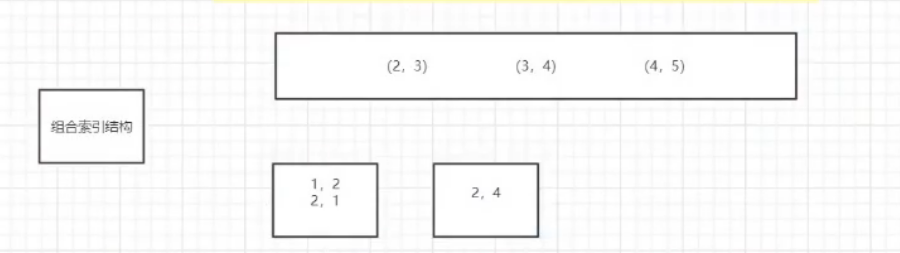
假设有1张表,有id name age gender 4个字段,id是主键,name,age是组合索引。组合索引使用的时候必须先匹配name,然后匹配age.
--会用索引
select * from table where name=? and age=?
--会用索引
select * from table where name=?
--不用索引
select * from table where age=?
--会用索引(mysql内部优化器会调整对应的顺序)
select * from table where age=? and name=?
索引下推 5.7之后默认支持(select @@optimizer_switch;)
select * from table where name=? and age=?
- 在没有索引下推之前:根据name从存储引擎中获取符合规则的数据,然后再server层对age进行过滤
- 有索引下推之后:根据name,age两个条件来从存储引擎中获取对应的数据。减少server与存储引擎间的io.
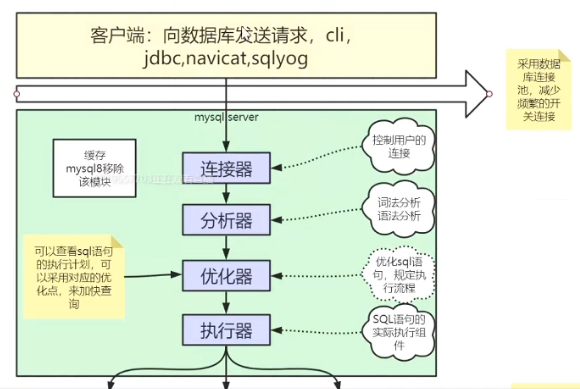
mysql三层架构 client-->server-->存储引擎
mysql设计主键时要不要自增,主键自增的好处是数据块不会分裂,(例如一个block存放11,12,13,15。插入14,如果block放不下了需要分裂,对应的上层节点也需要修改)
- myisam与innodb部分区别
| myisam | innodb |
|---|---|
| 索引结构不同 | 索引结构不同 |
| 表锁 | 表和行锁 |
| -- | 外键支持 |
| -- | 事物支持 |
Innodb行锁的实现方式
Innodb行锁是通过给索引上的索引项加锁实现的(oracle是对数据块中相应数据行加锁实现)。innodb:只有通过索引条件检索数据才使用行级锁,否则使用表锁。
实验1:创建一个无索引的表,插入数据,set autocommit=0 ,使用select * from table where id=1 for update查询,再另外一个session中也是用此查询查询id=2会发现表被锁。 实验2:创建id为索引再次重复实验1,结果不同。
主从复制
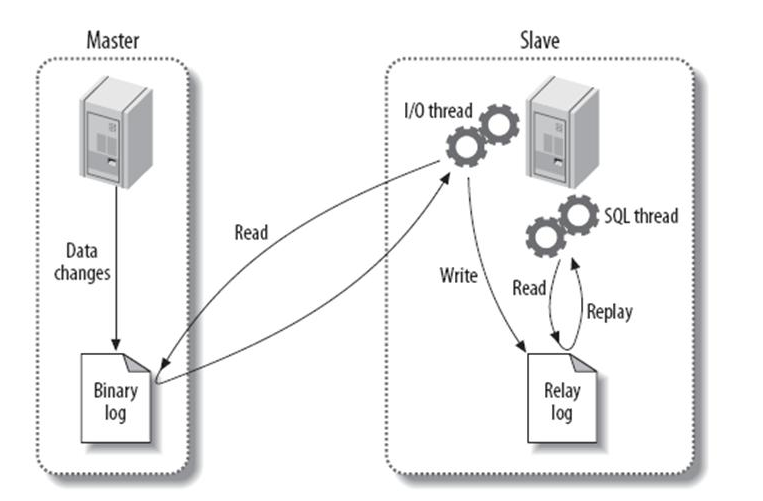
- binlog: 是记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。 (DDL和DML日志)与存储引擎无关,mysql server级别,如果数据库误删除可以用binlog+备份进行恢复。
- redo log: innodb级别,前滚日志,指事务中操作的任何数据,将最新的数据备份到一个地方
- undo log: innodb级别,回滚日志,指事务开始之前, 在操作任何数据之前,首先将需操作的数据备份到一个地方

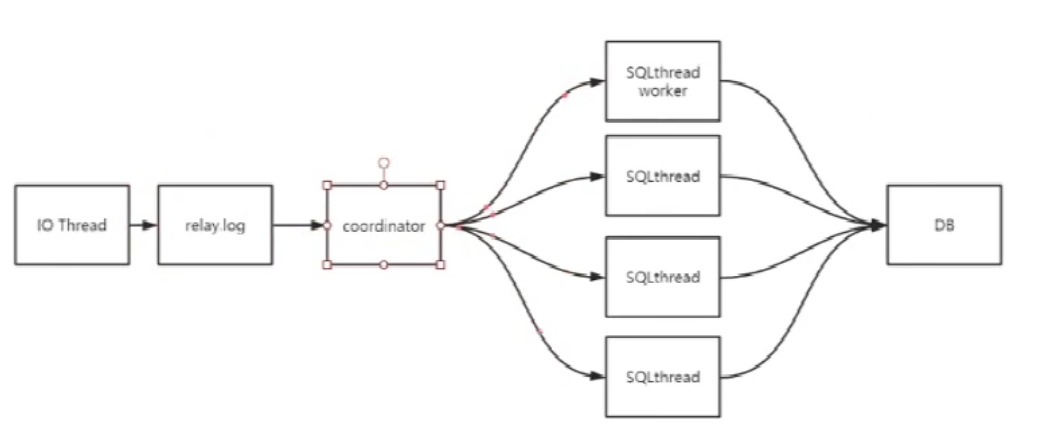
设置多个slave sql thread worker,show variables like '%worker%';

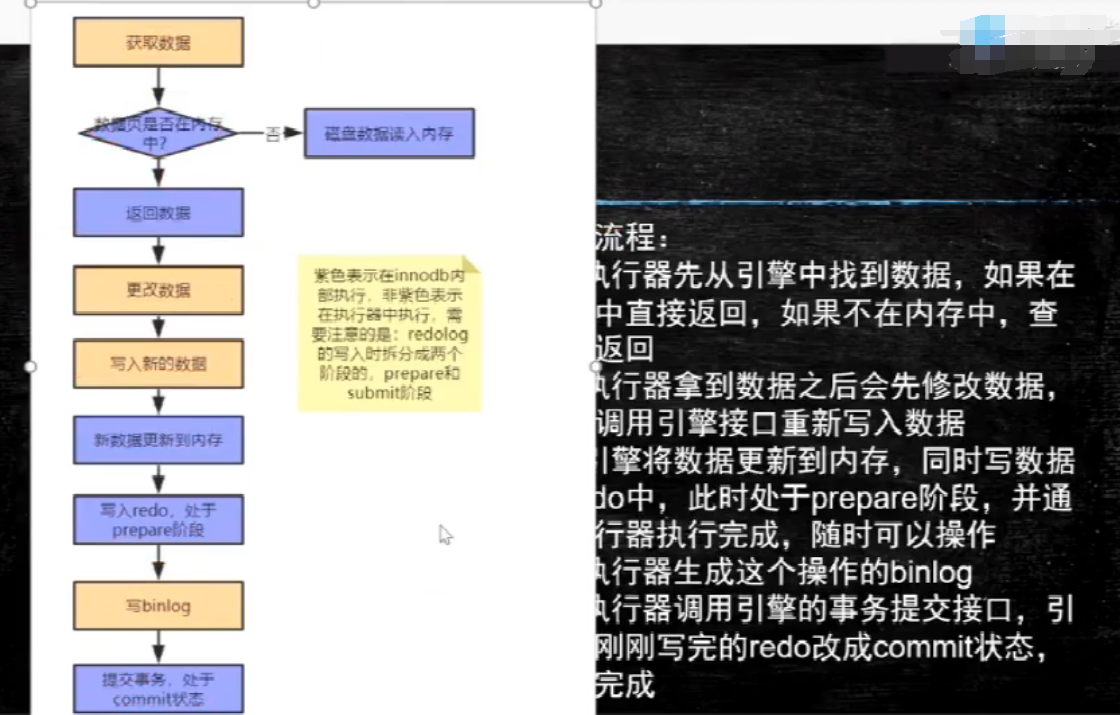
(数据写过程--先写入进程buffer--write到OS buffer -- sync到磁盘)
GTID(存储组提交的相关的信息 ;组提交 binlog中有last_commit与sequence_number )GTID( Global Transaction Identifier)全局事务标识,由主库上生成的与事务绑定的唯一标识,这个标识不仅在主库上是唯一的,在MySQL集群内也是唯一的。GTID是 MySQL 5.6 版本引入的一个有关于主从复制的重大改进,相对于之前版本基于Binlog文件+Position的主从复制,基于GTID的主从复制,数据一致性更高,主从数据复制更健壮,主从切换、故障切换不易出错,很少需要人为介入处理。GITD是对于一个已提交事务的编号,并且是一个全剧唯一的编号,GTID实际上是由UUID+TID组成,UUID是mysql实例的唯一标示,tid是该实例上已经提交的事务数量,并且随着事务提交单调递增。这种方式保证事务在集群中有唯一的ID,强化了主备一致和故障恢复能力。
