centos7部署Ceph存储
ceph简介
Ceph的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,使数据能容错和无缝的复制。支持对象存储、块存储、文件系统存储应用。
| 特性 | 描述 |
|---|---|
| 扩展性 | 使用普通x86服务器,支持1000节点服务器集群,容量从TB到EB扩展 |
| 可靠性 | 无单点故障、多数据副本、自动修复、自动管理 |
| 高性能 | 数据均匀分布 |
| 适用范围广 | 对象存储、块设备存储、文件系统存储 |
Ceph架构:
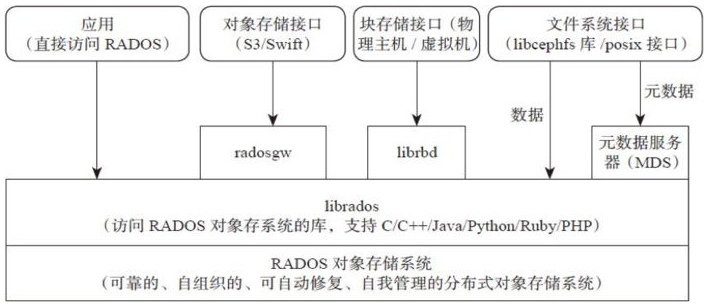
| 架构 | 描述 |
|---|---|
| RADOS | Reliable Autonomic Distributed Object Store。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。 |
| librados | librados库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。 |
| RADOSGW | 网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift 兼容的RESTful API接口。 |
| RBD | 块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。 |
| CephFS | Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口。 |
Ceph组件
ceph组件 | 描述 osd | 即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor monitor | 监视器,维护集群状态的多种映射,同时提供认证和日志记录服务,包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过 "ceph mon dump"查看 monitor map。 MDS(Metadata Server)|Ceph 元数据,主要保存的是Ceph文件系统的元数据。注意:ceph的块存储和ceph对象存储都不需要MDS。CEPHFS需要配合MDS节点。 Manager(ceph-mgr) | 收集集群信息,提供ceph dashboard和resetful api.
ceph部署
部署
| 主机 | IP | 角色 |
|---|---|---|
| cephadm | 192.168.171.128 | admin |
| node1 | 192.168.171.129 | osd,mon,mgr |
| node2 | 192.168.171.130 | osd,mon,mgr |
| node3 | 192.168.171.131 | osd,mon,mgr |
| client1 | 192.168.171.132 | 测试客户端 |
- 配置
配置/etc/hosts(省略操作) 关闭防火墙(省略操作) 关闭selinux(省略操作) 修改hostname(可选)(省略操作) osd机器都配置了6G的sdb磁盘(6G盘仅用于本文演示,生产根据自己需求)(省略操作) 确保时钟同步(省略操作)
#hosts
[root@localhost ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.171.128 cephadm
192.168.171.129 node1
192.168.171.130 node2
192.168.171.131 node3
192.168.171.132 client1
#磁盘
[root@node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 80G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 79G 0 part
├─centos-root 253:0 0 50G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 27G 0 lvm /home
sdb 8:16 0 6G 0 disk
sr0 11:0 1 4.4G 0 rom
配置yum源(所有节点)
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
cat > /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=ceph
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/x86_64/
gpgcheck=0
[ceph-noarch]
name=cephnoarch
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch/
gpgcheck=0
EOF
yum clean all && yum makecache
配置admin节点免密登陆其它机器
[root@cephadm ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:JXhOCF8tSL7b5arvBZiSRqJhOJD0v2UV5WSGPTf5zUw root@cephadm
The key's randomart image is:
+---[RSA 2048]----+
|oo .....o+= . |
|+ . +.+..Bo + E|
|+.... = +o..o o+.|
|.+ o.. B.o .+|
|. +.+oS . |
| . .+o + |
| .. . o |
| o |
| .++ |
+----[SHA256]-----+
[root@cephadm ~]# ssh-copy-id root@cephadm
[root@cephadm ~]# ssh-copy-id root@node1
[root@cephadm ~]# ssh-copy-id root@node2
[root@cephadm ~]# ssh-copy-id root@node3
[root@cephadm ~]# ssh-copy-id root@client1
安装ceph-deploy(cephadm节点,如果用普通用户安装需要配置sudo权限,这里用root安装)
[root@cephadm ~]# yum -y install ceph-deploy python-setuptools
#先在管理节点上创建一个目录,用于保存 ceph-deploy 生成的配置文件和密钥对。
[root@cephadm ~]# mkdir /etc/ceph
[root@cephadm ~]# cd /etc/ceph/
#ceph-deploy 会把文件输出到当前目录,所以请确保在此目录下执行 ceph-deploy 。
#创建集群ceph-deploy new {initial-monitor-node(s)}
[root@cephadm ceph]# ceph-deploy new node1 node2 node3
#新集群被自动命名为ceph,集群创建完成后,在/etc/ceph/目录中会产生ceph配置文件、monitor秘钥文件和log文件
[root@cephadm ceph]# ll
total 16
-rw-r--r-- 1 root root 244 Jan 25 10:15 ceph.conf
-rw-r--r-- 1 root root 5041 Jan 25 10:15 ceph-deploy-ceph.log
-rw------- 1 root root 73 Jan 25 10:15 ceph.mon.keyring
#修改配置文件
[root@cephadm ceph]# vim ceph.conf
[global]
fsid = 323c8265-6cb9-4d21-b54a-404d0ff200d4
mon_initial_members = node1
mon_host = 192.168.171.129
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 2 #设置默认副本数为2 默认为3
#rbd_default_features = 1 #永久改变默认值
#osd journal size = 2000 #日志大小设置
#public network = 192.168.171.0/24 #如果有多个网卡则需进行网络配置
#如果是ext4的文件格式需要执行下面两个配置 (df -T -h|grep -v var查看格式)
#osd max object name len = 256
#osd max object namespace len = 64
#在各节点安装 Ceph ,会通过yum安装ceph ceph-radosgw 的rpm包
[root@cephadm ceph]# ceph-deploy install node1 node2 node3 --repo-url=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/
初始化集群
#配置初始 monitor(s)、并收集所有密钥
[root@cephadm ceph]# ceph-deploy mon create-initial
[root@cephadm ceph]# ll
total 412
-rw------- 1 root root 113 Jan 22 15:50 ceph.bootstrap-mds.keyring
-rw------- 1 root root 71 Jan 22 15:50 ceph.bootstrap-mgr.keyring
-rw------- 1 root root 113 Jan 22 15:50 ceph.bootstrap-osd.keyring
-rw------- 1 root root 113 Jan 22 15:50 ceph.bootstrap-rgw.keyring
-rw------- 1 root root 129 Jan 22 15:50 ceph.client.admin.keyring
-rw-r--r-- 1 root root 615 Jan 22 15:50 ceph.conf
-rw-r--r-- 1 root root 144362 Jan 22 15:50 ceph-deploy-ceph.log
-rw------- 1 root root 73 Jan 22 15:13 ceph.mon.keyring
#用 ceph-deploy 部署完成后它会自动启动集群(此时只启动了ceph-mon)。
[root@node1 ~]# ps aux | grep ceph
ceph 12456 0.1 2.2 331136 21912 ? Ssl 15:50 0:00 /usr/bin/ceph-mon -f --cluster ceph --id node1 --setuser ceph --setgroup ceph
root 12883 0.0 0.0 112808 964 pts/0 R+ 15:56 0:00 grep --color=auto ceph
#可以在mon节点查看ceph状态
[root@node1 ceph]# ceph status
cluster:
id: f13f7b61-f78c-4141-ba55-8eac59d0fdeb
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点,这样你每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了。
#格式ceph-deploy admin {admin-node} {ceph-node}
[root@cephadm ceph]# ceph-deploy admin node1 node2 node3
#在其他节点验证
[root@node2 ~]# ll /etc/ceph/
total 12
-rw------- 1 root root 129 Jan 22 16:33 ceph.client.admin.keyring
-rw-r--r-- 1 root root 615 Jan 22 16:33 ceph.conf
-rw-r--r-- 1 root root 92 Jul 10 2018 rbdmap
-rw------- 1 root root 0 Jan 22 16:33 tmpT87T14
安装ceph-mgr
配置osd(注意主机名与磁盘,根据需要修改)
# 使用create 命令,就无需依次执行 prepare 和 activate 命令。会自动创建数据分区和日志分区,格式化,启动ceph.target服务
[root@cephadm ceph]# ceph-deploy osd create node1 --data /dev/sdb
[root@cephadm ceph]# ceph-deploy osd create node2 --data /dev/sdb
[root@cephadm ceph]# ceph-deploy osd create node3 --data /dev/sdb
#systemctl status ceph.target
# netstat -lpnt 在osd节点查看
创建mon节点
[root@cephadm ceph]# ceph-deploy mon create node1 node2 node3
创建mgr
[root@cephadm ceph]# ceph-deploy mgr create node1 node2 node3
集群常用操作(在node123节点可用):
#查看状态
[root@node1 ceph]# ceph -s
cluster:
id: f13f7b61-f78c-4141-ba55-8eac59d0fdeb
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active), standbys: node2, node3
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 3.01GiB used, 12.0GiB / 15.0GiB avail
pgs:
#健康检查
[root@node1 ceph]# ceph health
HEALTH_OK
#ceph-deploy osd list node1
#ceph df
#ceph osd tree
## ceph quorum_status --format json-pretty 查看mon状态
## systemctl restart ceph.target 一次性重启全部服务
#systemctl status ceph-mon.target
# ceph --version
ceph dashboard开启
在node1操作(不同的ceph发行版,安装配置方式会有差异)
[root@node1 ceph]# ceph mgr module enable dashboard
#访问:http://IP:7000/
# 设置dashboard 端口和IP
#ceph config-key set mgr/dashboard/server_port 7000 (可以不用配置,默认端口7000)
#ceph config-key set mgr/dashboard/server_addr $IP (可以不用配置,指定集群 dashboard的访问IP)
配置客户端使用rbd
先创建存储池pool,在mon节点(node1)执行(luminous版本,创建集群时,不会自动创建默认’rbd’池)
#创建存储池: ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated] [crush-ruleset-name] [expected-num-objects]
#删除存储池: ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
#重命名存储池: ceph osd pool rename {current-pool-name} {new-pool-name}
#少于 5 个 OSD 时可把 pg_num 设置为 128,OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512,OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096,OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
[root@node1 ceph]# ceph osd pool create testrdb 128 128
pool 'testrdb' created
#查看寄存pool
[root@node1 ceph]# ceph osd lspools
1 testrdb,
#设置pool的类型(ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications)
[root@node1 ceph]# ceph osd pool application enable testrdb rbd
enabled application 'rbd' on pool 'testrdb'
创建块设备镜像,在mon节点(node1)执行
#创建块设备镜像命令是rbd create --size {megabytes} {pool-name}/{image-name},如果pool_name不指定,则默认的pool是rbd,下面创建2G的块设备
[root@node1 ceph]# rbd create --size 2048 test_image -p testrdb
#(删除镜像: rbd rm testrdb/test_image)
#查看块设备的命令是rbd info {pool-name}/{image-name}
[root@node1 ceph]# rbd info testrdb/test_image
rbd image 'test_image':
size 2GiB in 512 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.5e626b8b4567
format: 2
#features,是这个块设备支持的特性,可以关闭指定的特性
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
create_timestamp: Mon Jan 25 13:38:10 2021
client1客户端安装ceph
#在cephadm机器操作(也可以手动在client1安装,然后cp相关配置文件)
[root@cephadm ceph]# ceph-deploy install client1 --repo-url=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/
#同步管理配置
[root@cephadm ceph]# ceph-deploy admin client1
本地映射,在client1机器执行
#特性不支持,要么升级内核,要么关闭一些特性,这里关闭特性(也可以创建rbd之前设置配置文件的rbd_default_features选项)。
[root@client1 ~]# rbd map testrdb/test_image
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable testrdb/test_image object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
#关闭特性
[root@client1 ~]# rbd feature disable testrdb/test_image object-map fast-diff deep-flatten
#再次映射:
[root@client1 ~]# rbd map testrdb/test_image
/dev/rbd0
#取消映射使用rbd unmap testrdb/test_image
#查看当前映射 rbd showmapped
格式化并挂载
#格式化,注意xfs不支持收缩
[root@client1 ~]# mkfs.xfs /dev/rbd/testrdb/test_image
Discarding blocks...Done.
meta-data=/dev/rbd/testrdb/test_image isize=512 agcount=8, agsize=65536 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=524288, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
#挂载
[root@client1 ~]# mkdir /mnt/textceph
[root@client1 ~]# mount /dev/rbd/testrdb/test_image /mnt/textceph
[root@client1 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 50G 1.7G 49G 4% /
/dev/sda1 1014M 138M 877M 14% /boot
/dev/mapper/centos-home 27G 33M 27G 1% /home
tmpfs 98M 0 98M 0% /run/user/0
/dev/rbd0 2.0G 33M 2.0G 2% /mnt/textceph
扩容rbd
#命令帮助rbd help resize
[root@client1 ~]# rbd resize -p testrdb --image test_image --size 3072
Resizing image: 100% complete...done.
#查看映射出来的块设备
[root@client1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
#.....省略部分输出
rbd0 252:0 0 3G 0 disk /mnt/textceph
#grow data/metadata section
[root@client1 ~]# xfs_growfs -d /mnt/textceph/
[root@client1 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
#.....省略部分输出
/dev/rbd0 3.0G 33M 3.0G 2% /mnt/textceph
配置cephfs
文件系统方式使用ceph,CephFS支持多节点挂载,kernel cephfs接口的性能略好于ceph-fuse. 下面开始安装:先启用mds服务(在cephadm节点执行)
- 确保已经通过cephadm节点管理了client1节点(ceph-deploy install client1)
[root@cephadm ceph]# ceph-deploy mds create node1
创建CephFS需要的metadata 和 data pools
[root@node1 ceph]# ceph osd pool create cephfs_data 128
[root@node1 ceph]# ceph osd pool create cephfs_metadata 100
创建CephFS filesystem.
[root@node1 ceph]# ceph fs new test_cfs cephfs_metadata cephfs_data
new fs with metadata pool 3 and data pool 2
挂载方式一:fuse挂载
[root@client1 ~]# yum -y install ceph-fuse ceph
[root@client1 ~]# mkdir /mnt/fuseceph
[root@client1 ~]# ceph-fuse -m node1:6789 /mnt/fuseceph/
ceph-fuse[13839]: starting ceph client
2021-01-25 15:43:19.740027 2ab2d2e2ca00 -1 init, newargv = 0x55c51368d2c0 newargc=9
ceph-fuse[13839]: starting fuse
挂载方式二: kernel module
[root@client1 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQAhLQ5gxBG4BBAAxNCkRIL13Tx8kiU0fGA6NQ==
[root@client1 ~]# mount -t ceph 192.168.171.129:6789:/ /mnt/cephfs/ -o name=admin,secret=AQAhLQ5gxBG4BBAAxNCkRIL13Tx8kiU0fGA6NQ==
删除cephfs
#开启删除功能,在所有的mon节点执行
[root@node1 ceph]# vim /etc/ceph/ceph.conf
[global]
fsid = f13f7b61-f78c-4141-ba55-8eac59d0fdeb
mon_initial_members = node1, node2, node3
mon_host = 192.168.171.129,192.168.171.130,192.168.171.131
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 2
mon_allow_pool_delete = true
[root@node1 ceph]# systemctl restart ceph-mon.target
#删除cephfs先停止mds
[root@node1 ceph]# systemctl stop ceph-mds.target
[root@node1 ceph]# ceph mds fail 0
[root@node1 ceph]# ceph mds stat
test_cfs-0/1/1 up , 1 failed
#删除cephfs test_cfs
[root@node1 ceph]# ceph fs rm test_cfs --yes-i-really-mean-it
#删除对应的pool
[root@node1 ceph]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
pool 'cephfs_metadata' removed
[root@node1 ceph]# ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it
pool 'cephfs_data' removed
ceph对象存储
#从管理节点的工作目录,在 client1 上安装 Ceph 对象网关软件包
[root@cephadm ceph]# ceph-deploy install --rgw client1
#修改端口
[root@cephadm ceph]# vim ceph.conf
[global]
fsid = f13f7b61-f78c-4141-ba55-8eac59d0fdeb
mon_initial_members = node1, node2, node3
mon_host = 192.168.171.129,192.168.171.130,192.168.171.131
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 2
[client.rgw.client1]
rgw_frontends = "civetweb port=80"
[root@cephadm ceph]# ceph-deploy --overwrite-conf admin client1
#创建rgw实例
[root@cephadm ceph]# ceph-deploy rgw create client1
#在client1上查看监听
[root@client1 ~]# systemctl status ceph-radosgw.target
[root@client1 ~]# netstat -tunlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 14950/radosgw
访问80端口测试
想正常的访问RGW,需要创建相应的RGW用户,并赋予相应的权限,radosgw-admin命令实现了这些功能。执行下面命令,来创建一个名为testuser的用户(在client1机器执行)
#在client1机器执行,access_key与secret_key后面会用到
[root@client1 ~]# radosgw-admin user create --uid="testuser" --display-name="Test User"
{
"user_id": "testuser",
"display_name": "Test User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "testuser",
"access_key": "9CP0O2ELR17ENGCRMECK",
"secret_key": "lsIW0e5n6NnTojtPW6z4FmUdlRJYko4LNM3IBvqW"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw"
}
创建Swift用户,Swift用户是作为子用户subuser被创建的
[root@client1 ~]# radosgw-admin subuser create --uid=testuser --subuser=testuser:swift --access=full
{
"user_id": "testuser",
"display_name": "Test User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [
{
"id": "testuser:swift",
"permissions": "full-control"
}
],
"keys": [
{
"user": "testuser",
"access_key": "9CP0O2ELR17ENGCRMECK",
"secret_key": "lsIW0e5n6NnTojtPW6z4FmUdlRJYko4LNM3IBvqW"
}
],
"swift_keys": [
{
"user": "testuser:swift",
"secret_key": "jhU7kMKjM7IT1wsOEMCcIzBCgaENMW8Zgl9ur2EG"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw"
}
S3接口测试。创建一个Python测试脚本来测试S3访问。该脚本会连接RGW,创建一个bucket并列出所有的bucket。其中,变量access_key和secret_access的值,来自于创建S3用户命令时,radosgw-admin命令返回的keys->access_key和keys->secret_key
[root@client1 ~]# yum -y install python-boto
[root@client1 ~]# vim s3test.py
import boto.s3.connection
access_key = '9CP0O2ELR17ENGCRMECK'
secret_key = 'lsIW0e5n6NnTojtPW6z4FmUdlRJYko4LNM3IBvqW'
conn = boto.connect_s3(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
host='client1', port=80,
is_secure=False, calling_format=boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('my-test-bucket')
for bucket in conn.get_all_buckets():
print "{name} {created}".format(
name=bucket.name,
created=bucket.creation_date,
)
[root@client1 ~]# python s3test.py
my-test-bucket 2021-01-25T08:48:45.961Z
Swift接口测试
[root@client1 ~]# yum -y install python-swiftclient
#swift -A http://{IP ADDRESS}:{port}/auth/1.0 -U testuser:swift -K '{swift_secret_key}' list
#替换{IP ADDRESS}、{port}、{swift_secret_key}等相关参数,其中{swift_secret_key}为创建Swift用户时,radosgw-admin命令返回的swift_keys->secret_key的值。